July 31, 2006
Notes from a talk about DiamondTouch
I went to another University of Colorado computer science colloquium last week, covering Selected HCI Research at MERL Technology Laboratory. I've blogged about some of the talks I've attended in the past.
This talk was largely about the DiamondTouch, but an overview of Mitsubishi Electronic Research Laboratories was also given. The DiamondTouch is essentially a tablet PC writ large--you interact through a touch screen. The biggest twist is that the touch screen can actually differentiate users, based on electrical impulses (you sit on special pads which, I believe, generate the needed electrical signatures). To see the DiamondTouch in action, check out this YouTube movie showing a user playing World Of Warcraft on a DiamondTouch. (For more on YouTube licensing, check out the latest Cringely column.)
What follows are my loosely edited notes from the talk by Kent Wittenburg and Kathy Ryall.
[notes]
First, from Kent Wittenburg, one of the directors of the lab:
MERL is a research lab. They don't do pure research--each year they have a numeric goal of business impacts. Such impacts can be a standards contribution, a product, or a feature in a product. They are associated with Mitsubishi Electric (not the car company).
Five areas of focus:
- Computer vision--2D/3D face detection, object tracking
- Sensor and data--indoor networks, audio classification
- Digital Communication--UWB, mesh networking, ZigBee
- Digital Video--MPEG encoding, highlights detection, H.264. Interesting anecdote--realtime video processing is hard, but audio processing can be easier, so they used audio processing to find highlights (GOAL!!!!!!!!!!!!) in sporting videos. This technology is currently in a product distributed in Japan.
- Off the Desktop technologies--touch, speech, multiple display calibration, font technologies (some included in Flash 8), spoken queries
The lab tends to have a range of time lines--37% long term, 47% medium and 16% short term. I think that "long term" is greater than 5 years, and "short term" is less than 2 years, but I'm not positive.
Next, from Kathy Ryall, who declared she was a software person, and was focusing on the DiamondTouch technology.
The DiamondTouch is multiple user, multi touch, and can distinguish users. You can touch with different fingers. The screen is debris tolerant--you can set things on it, or spill stuff on it and it continues to work. The DiamondTouch has legacy support, where hand gestures and pokes are interpreted as mouse clicks. The folks at MERL (and other places) are still working on interaction standards for the screen. The DiamondTouch has a richer interaction than the mouse, because you can use multi finger gestures and pen and finger (multi device) interaction. It's a whole new user interface, especially when you consider that there are multiple users touching it at one time--it can be used as a shared communal space; you can pass documents around with hand gestures, etc.
It is a USB device that should just plug in and work. There are commercial developer kits available. These are available in C++, C, Java, Active X. There's also a Flash library for creating rapid prototype applications. DiamondSpin is an open source java interface to some of the DiamondTouch capabilities. The folks at MERL are also involved right now in wrapping other APIs for the DiamondTouch.
There are two sizes of DiamondTouch--81 and 107 (I think those are the diagonal measurements). One of these tables costs around $10,000, so it seems limited to large companies and universities for a while. MERL is also working on DiamondSpace, which extends the DiamondTouch technology to walls, laptops, etc.
[end of notes]
It's a fascinating technology--I'm not quite sure how I'd use it as a PC replacement, but I could see it (once the cost is more reasonable) but I could see it as a bulletin board replacement. Applications that might benefit from multiple user interaction and a larger screen (larger in size, but not in resolution, I believe), like drafting and gaming, would be natural for this technology too.
How green is your computer?
Find out at the Electronic Product Environmental Assessment Tool.
July 14, 2006
Another RSS To Email site
Along the lines of Squeet, which I mentioned previously, it looks like Craig2Mail does a good job of converting RSS feeds to emails.
July 05, 2006
Paper examining on the fly compression
I found this paper (PDF), while a bit old (from 2002), to be a useful analysis of on the fly compression (a la mod_gzip or mod_deflate).
June 21, 2006
How to receive craigslist searches via email
craigslist is an online classified ad service, with everything from personals to real estate to bartering offered online. I've bought a table from Denver's craigslist and I know a number of folks who have found roommates via craigslist.
If you have a need that isn't available right now, you can subscribe to a search of section of craigslist. Suppose you're looking for a used cruiser bike in Denver, you can search for cruisers and check out the current selection. If you don't like what you see but don't want to keep coming back, you can use the RSS feed link for the search, which is at the lower right corner. Put this link into your favorite RSS reader (this is a simple application that manages RSS feeds, which are essentially lists of links. I'd recommend Bloglines but there are many others out there) and you can be automatically apprised of any new cruisers which are posted.
(You find tons of stuff via RSS--stock quotes, job listings, paparazzi photos... The list is endless.)
If you don't want to deal with yet another application, or you're not always in your RSS reader (like me), you can set up an RSS to email gateway. That way, if your cruiser bike search is so urgent you don't want to let a good deal get away, you receive notification of a new posting relatively quickly. If you want, you can even email it to your mobile phone.
The basic steps:
- Go to the Squeet signup page. Sign up for a free account. Don't forget to verify it--they'll send an email to the address you give them.
- Open up a new browser window and go to craigslist, choose the city/section you are interested in, and do a search. The example up above was 'cruiser', in the bike section of the Denver CL.
- Scroll down to the bottom of the search results and right click on the RSS link. Choose either 'Copy Shortcut' or 'Copy Link Location', depending on your browser.
- Switch back to the Squeet window, and click in the 'FEED URL' box. Paste in the link you just copied. Choose your notification time period--I'd recommend a frequency of 'live', since cruiser bikes in the Denver area tend to move pretty quick. Then click the subscribe button.
That's it. Just wait for the emails to roll in and soon enough you'll find the cruiser bike of your dreams. Just be aware that it's not real time--I've seen lags from 30 minutes to 2 hours from post to email. Still, it's a lot easier that clicking 'Refresh' on your browser all day and night.
June 20, 2006
Google offers geocoding
Google now offers geocoding services. Up to 50,000 addresses a day. I built a geocoding service from the Tiger/Line database in the past. Comparing its results with the Google geocoding results, and Google appears to be a bit better. I've been looking around the Google Maps API discussion group and the Google Maps API Blog and haven't found any information on the data sources that the geocoding service uses or the various levels of precision available.
June 09, 2006
Naymz.com Launched
A friend has been working on a startup which looks like it's been focusing on identity management on the internet. That startup, Naymz, launched today. I just joined--check out my page. It'll be interesting to see if this site fills a need.
June 06, 2006
Google does spreadsheets
Check out spreadsheets.google.com. Limited time look at what javascript can do for a spreadsheet. I took a quick look and it seems to fit large chunks of what I use Excel or calc, the OpenOffice spreadsheet program, for. Just a quick tour of what I such spreadsheet programs for, and what Google spreadsheet supports:
- cut and paste, of text and formulas
- control arrow movement and selection
- formatting of cells
- merging of cells and alignment of text in cells
- undo/redo that goes at least 20 deep
- sum/count
- can freeze rows
- share and save the spreadsheet
- export to csv and xls
On the other hand, no:
- dragging of cells to increment them (first cell is 45, next is 46, 47...).
- using the arrows to select what goes into a formula--you can type in the range or use the mouse
Pretty decent for a web based application. And it does have one killer feature--updates are immediatly propagated (I have never tried to do this with a modern version of Excel, so don't know if that's standard behaviour). Snappy enough to use, at least on my relatively modern computer. I looked at the js source and it's 55k of crazy javascript (Update, 6/9: This link is broken.). Wowsa.
I've never used wikicalc but it looks more full featured that Google spreadsheets. On the other hand, Google spreadsheets has a working beta version...
This and the acquisition of writely make me wonder if some folks are correct when they doubt that Google will release a software productivity suite. (More here.) Other interesting comments from Paul Kedrosky.
I know more than one person that absolutely depend on gmail for business functionality, which spooks me. And in some ways, I agree with Paul, it appears that Google "...takes a nuclear winter approach wherein it ruins markets by freezing them and then cutting revenues to zero."
Personally, if I don't pay for something, I'm always leery of it being taken away. Of course, if I pay, the service can also go away, but at least I have some more leverage with the company--after all, if they take the service away, they lose money.
May 25, 2006
Bloglines and SQL
I moved from my own personal RSS reader (coded in perl by yours truly) to Bloglines about a year ago. The main reason is that Bloglines did everything my homegrown reader did and was free (in $ and in time to maintain it).
But with over 1 billion articles served as of Jan 2006, I always wondered why Bloglines didn't do more collaborative filtering. They do have a 'related feeds' tab, but it doesn't seem all that smart (though it does seem to get somewhat better as you have more subscribers). I guess there are a number of possible reasons:
- It's easier to find feeds that look like they'd be worth reading (I have 180 feeds that I attempt to keep track of)
- blogrolls provide much of this kind of filtering at the user level
- privacy concerns?
- No demand from users
But this article, one of a series about data management in well known web applications, gives another possible answer: the infrastructure isn't set up for easy querying. Sayeth Mark Fletcher of bloglines:
As evidenced by our design, traditional database systems were not appropriate (or at least the best fit) for large parts of our system. There's no trace of SQL anywhere (by definition we never do an ad hoc query, so why take the performance hit of a SQL front-end?), we resort to using external (to the databases at least) caches, and a majority of our data is stored in flat files.
Incidentally, all of the articles in the 'Database War Stories' series are worth reading.
Using Grids?
Tim Bray gives a great write up of Grid Infrastructure projects. But he still doesn't answer Stephen's question: what is it good for?
I think the question is especially relevant for on demand 'batch grids', to use Tim's terms. A 'service grid' has uses that jump to mind immediately; scaling web serving content is one of them. But on demand batch grids (I built an extremely primitive one in college) are good for complicated processes that take a long time. I don't see a lot of that in my current work--but I'm sure my physics professor would be happy to partake.
May 03, 2006
Owen Taylor Blogging
Owen Taylor, who I pleaded (in person and in this blog) to start blogging, has done so. This is Owen Taylor's Weblog. If you're interested in jini, javaspaces or random technological musings, give it a look. Welcome, Owen!
April 19, 2006
apachebench drops hits when the concurrency switch is used
I've used apachebench (or ab), a free load testing tool written in C and often distributed with the Apache Web Server, to load test a few sites. It's simple to configure and gives tremendous throughput. (I was seeing about 4 million hits an hour over 1 gigabit ethernet. I saw about 10% of that from jmeter on the same machine; however, the tests that jmeter was running were definitely more compex.)
Apachebench is not perfect, though. The downsides are that you can only hit one url at a time (per ab process). And if you're trying to load test the path through a system ("can we have folks login, do a search, view a product and logout"), you need to map that out in your shell script carefully. Apachebench has no way to create more complicated tests (like jmeter can). Of course, apachebench doesn't pretend to be a system test tool--it just hits a set of urls as fast as it can, as hard as it can, just like a load tool should.
However, it would be nice to be able to compare hits recieved on the server side and the log file generated by apachebench; the numbers should reconcile, perhaps with some fudge factor for network errors. I have found that these numbers reconcile as long as you only have one client (-c 1, or the default). Once you start adding clients, the server records more hits than apachebench. This seems to be deterministic (that is, repeatable), and worked out to around 4500 extra requests for 80 million requests. As the number of clients approached 1, the discrepancy between the server and apachebench numbers decreased as well.
This offset happened with Tomcat 5 and Apache 2, so I don't think that the issues is with the server--I think apachebench is at fault. I searched the httpd bug database but wasn't able to find anything related. Just be aware that apachebench is very useful for generating large HTTP request loads, but if you need to reconcile for accuracy, skip the concurrency offered.
April 08, 2006
The Eolas Matter, or How IE is Going to Change 'Real Soon Now'
Do you use <object> functionality in your web application? Do you support Microsoft Internet Explorer?
If so, you might want to take a look at this: Microsoft's Active X D-Day, which details Microsoft's plans to change IE to deal with the Eolas lawsuit. Apparently the update won't be critical, but eventually will be rolled into every version of IE.
Here's a bit more technical explanation of what how to fix object embedding from Microsoft, and a bit of history from 2003.
Via Mezzoblue.
March 22, 2006
A survey of geocoding options
I wrote a while back about building your own geocoding engine. The Tiger/Line dataset has some flaws as a geocoding service, most notably that once you get out of urban areas many addresses simply cannot be geocoded.
Recently, I was sent a presentation outlining other options (pdf) which seems to be a great place to start an evaluation. The focus is on Lousiana--I'm not sure how the conclusions would apply to other states' data.
March 20, 2006
Newsgator goes mobile
Congratulations to Kevin Cawley, whose mobile products company has been acquired by Newsgator. I know Kevin peripherally (we talked about J2ME once or twice) and wish him luck in his new job.
Folks whose opinion I respect really like Newsgator for RSS aggregation; it'll be interesting to see how they react when Outlook 12 is released with RSS aggregation built in.
March 14, 2006
Full content feeds and Yahoo ads
I changed the Movable Type template to include full content on feeds. Sorry for the disruption (it may have made the last fifteen entries appear new).
I think sending full content in the feeds (both RSS1 and RSS2) goes nicely with the Yahoo Ads I added a few months ago. Folks who actually subscribe to what I say shouldn't have to endure ads, while those who find the entries via a search engine can endure some advertising. (Russell Beattie had a much slicker implementation of this idea a few years ago.)
More about the ads: I think that they're not great, but I think that's due to my relative lack of traffic--because of the low number of pageviews, Yahoo just doesn't (can't) deliver ads that are very targeted. (I've seen a lot of 'Find Dan Moore'). It's also a beta service (ha, ha). Oh well--it has paid me enough to go to lunch (but I'll have to wait because they mail a check only when you hit $100).
As long as we're doing public service announcements, I've decided to turn off comments (from the initial post, rather than only on the old ones). Maybe it's because I'm posting to thin air, or because I'm not posting on inflammatory topics, or because comment spam is so prevalent, but I'm not getting any comments anymore (I think 5 in the last 6 months). So, no more comments.
And that's the last blog about this blog you'll see, hopefully for another year.
February 19, 2006
Choosing a wiki
I am setting up a wiki at work. These are our requirements:
- File based storage--so I don't have to deal with installing a database on the wiki server
- Authentication of some kind--so that we can know who made changes to what document
- Versioning--so we can roll back changes if need be.
- PHP based--our website already runs php and I don't want to deal with alternate technologies if I don't have to.
- Handles binary uploads--in case someone had a legacy doc they wanted to share.
- Publish to PDF--so we can use this wiki for more formal documents. We won't publish the entire site, but being able to do this on a per document basis is required.
I started with PHPWiki but its support for PDF was lacking. (At least, I couldn't figure it out, even though it was documented.)
After following the wizard process at WikiMatrix (similar to CMSMatrix, which I've touched on before), I found PmWiki, which has support for all of our requirements. It also seems to have a nice extensible architecture.
Installation was a snap and after monkeying around with authentication and PDF installation (documented here), I've added the following lines to my local/config.php:
include_once('cookbook/pmwiki2pdf/pmwiki2pdf.php');
$EnablePostAuthorRequired = 1;
$EnableUpload = 1;
$UploadDir = "/path/to/wiki/uploads";
$UploadUrlFmt = "http://www.myco.com/wiki/uploads";
$UploadMaxSize = 100000000; // 100M
February 03, 2006
Google tricks
Not only can RSS get you a job and Google spare you from remembering URLs, but combining them lets you find when your namesake is in the news. Via the Justin Pfister RSS generator and Q Digital Studio.
February 02, 2006
Testing XMLHttpRequest's adherence to HTTP response codes
mnot has a set of tests looking at the behaviour of XMLHttpRequest as it follows various HTTP responses. Some of it is pretty esoteric (how many folks are using the DELETE method?--oh wait). But all in all it's interesting, especially given the buzz surrounding AJAX, of which XMLHttpRequest is a fundamental part.
February 01, 2006
Scott Davis pleads "Evolve" to Microsoft
An eloquent plea which points out some of the complexities of Microsoft's current situation. Microsoft, which had revenues of $9.74 billion in 2006 Q1 (with operating income of $4.05 billion), certainly isn't an industry darling anymore. I'm sure someone in Redmond is well aware that:
Once stalled, no U.S. company larger than $15 billion has been able to restart sustained double digit internal growth.
January 26, 2006
New bloggers
A couple of folks I've worked with in the past have begun blogging (or, have let me know they were blogging). They aren't developers, but do deal with the software world. (I'm shocked to note that both of their blogs are much snazzier than mine.)
Susan Mowery Snipes does web design. Her blog is company news and also exhibits the perspective of a UI focused designer--sometimes it's a bit through the looking glass (why would someone judge a website in 1/20 of second), but that's good for us software folks to take a look at.
And if a designer has a different view, a project manager is on a different planet. I admire the best PMs because they are able to manage even though they might not have any clue about technology details. Come to think of it, that may actually help. Regardless, Sarah Gilbert has been blogging for a while, but just shared the URL with me. She's an excellent writer and I am looking forward to reading more entries like Trust Me, You Don't Do Everything. I do wish she'd allow comments, though.
January 19, 2006
Software Licensing Haiku
I thought this list of software licensing haikus was pretty funny.
Kinda old, thought I'd update with some other licenses:
Apache: not the GPL! / we let you reuse to sell / you break it you buy
Creative Commons: choose one from many / confused? we will help whether / simple or sample
Berkley: do not remove the / notice, nor may you entangl' / berkeley in your mess
Artistic: tell all if you change / package any way you like / keep our copyright
January 08, 2006
Yahoo Ads
As you may have noticed, especially if you use an RSS reader, I've installed Yahoo Ads beta program on some of my pages. For the next few months, I plan to run Yahoo Ads on the individual article pages, as well as my popular JAAS tutorial.
I've not done anything like this before, but since I write internet software, and pay per click advertising is one of the main ways that such software makes money, I thought it'd be an interesting experiment. Due to the dictatorial Term and Conditions, I probably won't comment on any other facets of the ads in the future....
Please feel free to comment if you feel that the ads are unspeakably gauche--can't say I've been entirely happy with their targeting.
December 20, 2005
Mozilla, XPCOM and xpcshell
Most people know about mozilla through Firefox, their IE browser replacement. (Some geeks may remember the Netscape source code release.) But mozilla is a lot more than just a browser--there's an entire API set, XPCOM and XUL, that you can use to build applications. (There are books about doing so, but mozilla development seems to run ahead of them.) I'm working on a project that needs some custom browser action, so looking at XPCOM seemed a wise idea.
XPCOM components can be written in a variety of languages, but most of the articles out there focus on C++. While I've had doubts about scripting languages and large scale systems, some others have had success heading down the javascript path. I have no desire to delve into C++ any more than I have to (I like memory management), so I'll probably be writing some javascript components. Unfortunately, because XPCOM allows javascript to talk to C++, I won't be able to entirely avoid the issue of memory management.
xpcshell is an application bundled with mozilla that allows me to interact with mozilla's platform in a very flexible manner. It's more than just another javascript shell because it gives me a way to interact with the XPCOM API (examples). To install xpcshell (on Windows) make sure you download and install the zip file, not the Windows Installer. (I tried doing the complete install and the custom install, and couldn't figure out a way to get the xpcshell executable.)
One cool thing you can do with xpcshell is write command line javascript scripts. Putting this:
var a = "foobar";
print(a);
a=a.substr(1,2);
print(a);in a file named
test.js gives this output:
$ cat test.js | ./xpcshell.exe
foobar
oo
Of course, this code doesn't do anything with XPCOM--for that, see aforementioned examples.
I did run into some library issues running the above code on linux--I needed to execute it in the directory where xpcshell was installed. On windows that problem doesn't seem to occur.
A few other interesting links: installing xpcshell for firefox, firefox extensions with the mozilla build system, a javascript library easing XPCOM development, and another XPCOM reference.
December 01, 2005
Set up your own geocode service
Update, 2/9/06: this post only outlines how to set up a geocode engine for the United States. I don't know how to do it for any other countries.
Geocoder.us provides you with a REST based geocoding service, but their commercial services are not free. Luckily, the data they use is public domain, and there are some helpful perl modules which make setting up your own service a snap. This post steps you through setting up your own geocoding service (for the USA), based on public domain census data. You end up with a Google map of any address in the USA, but of course the lat/long you find could be used with any mapping service.
First, get the data.
$ wget -r -np -w 5 --random-wait ftp://www2.census.gov/geo/tiger/tiger2004se/
If you only want the data for one state, put the two digit state code at the end of the ftp:// url above (eg ftp://www2.census.gov/geo/tiger/tiger2004se/CO/ for Colorado's data).
Second, install the needed perl modules. (I did this on cygwin and linux, and it was a snap both times. See this page for instructions on installing to a nonstandard location with the CPAN module and don't forget to set your PERL5LIB variable.)
$ perl -MCPAN -e shell
cpan> install S/SD/SDERLE/Geo-Coder-US-1.00.tar.gz
cpan> install S/SM/SMPETERS/Archive-Zip-1.16.tar.gz
Third, import the tiger data (this code comes from the Geo::Coder::US perldoc, and took 4.5 hours to execute on a 2.6ghz pentium4 with 1 gig of memory). Note that if you install via the CPAN module as shown above, the import_tiger_zip.pl file is under ~/.cpan/:
$ find www2.census.gov/geo/tiger/tiger2004se/CO/ -name \*.zip
| xargs -n1 perl /path/to/import_tiger_zip.pl geocoder.db
Now you're ready to find the lat/long of an address. Find one that you'd like to map, like say, the Colorado Dept of Revenue: 1375 Sherman St, Denver, CO.
$ perl -MGeo::Coder::US -e 'Geo::Coder::US->set_db( "geocoder.db" );
my($res) = Geo::Coder::US->geocode("1375 Sherman St, Denver, CO" );
print "$res->{lat}, $ res->{long}\n\n";'
39.691702, -104.985361
And then you can map it with Google maps.
Now, why wouldn't you just use Yahoo!'s service (which provides geocoding and mapping APIs)? Perhaps you like Google's maps better. Perhaps you don't want to use a mapping service at all, you just want to find lat/longs without reaching out over the network.
November 03, 2005
Article on open formats
Gervase Markham has written an interesting article about open document formats. I did a bit of lurking on the bugzilla development lists for a while and saw Gervase in action--quite a programmer and also interested in the end user's experience. I think he raises some important issues--if html had been owned by a company, the internet (as the web is commonly known, even though it's only a part of the internet) would not be where it is today. If Microsoft Word (or WordPerfect) had opened up their document specification (or worked with other interested parties on a common one), other companies could have competed on features and consumers would have benefited. More on OpenDocument, including a link to a marked up version of a letter from Microsoft regarding the standard.
September 28, 2005
TheOnion on the 'WikiConstitution'
Seems like the Wikipedia model isn't for everyone: Congress abandons WikiConstitution.
August 07, 2005
Singing the praises of vmware
In the past few months, I've become a huge fan of vmware, the Workstation in particular. If you're not familiar with this program, it provides a virtual machine in which you can host an operating system. If you're developing on Windows, but targeting linux, you can run an emulated machine and deploy your software to it.
The biggest, benefit, however, occurs when starting a project. I remember at a company I worked at a few years ago, I was often one of the first people on a project. Since our technology stack often changed to meet the clients' needs, I usually had to learn how to install and troubleshoot a new piece of server software (ATG Dynamo, BEA Weblogic, Expresso, etc). After spending a fair amount of time making sure I knew how to install and deploy the new platform, I then wrote up terse yet complete (hopefully) installation documents for the future members of the team as the project rolled into development. Of course, that was not the end of it; there were slight differences in environment and user capability which meant that I was a resource for the rest of the team regarding platform configuration.
These factors made me a strong proponent of server based development, where you buy a high powered box and everyone develops (via CVS, samba or some other network protocol) and deploys (via a virtual server for each developer) to that box. Of course, setting it up is a hassle, but once it's done, adding new team members is not too much of a hassle. Compare this with setting up a windows box to do java development, and some of the complications that can ensue due to the differing environments.
But vmware changes the equation. Now, I, or someone like me, can create a development platform from scratch that includes everything from the operating system up. Combined with portable hard drives, which have become absurdly cheap (many gig for a few hundred bucks) you can distribute the platform to a new team member in less than hour. He or she can customize it, but if they ruin the image, it's easy enough to give the developer another copy. No weird operating system problems and no complicated dev server setup. This software saves hours and hours of development time and lets developers focus on code and not configuration. In addition, you can actually do development on an OS with a panoply of tools (Windows) and at the same time test deployment to a serious server OS (a UNIX of some kind).
However, there are still some issues to be aware of. That lack of knowledge often means that regular programmers can't help debug complicated deployment issues. Perhaps you believe that they shouldn't need to, but siloing the knowledge in a few people can lead to issues. If they leave, knowledge is lost, and other team members have no place to start when troubleshooting problems. This is, of course, an issue with or without vmware, but with vmware regular developers really don't even think about the install process; with an install document, they may not fully understand what they're doing, but probably have a bit more knowledge regarding deployment issues.
One also needs to be more vigilant than ever about keeping everything in version control; if the vmware platforms diverge, you're back to troubleshooting different machines. Ideally, everyone should mount a local directory as a network drive in vmware and use their own favorite development tools (Eclipse, netbeans, vi, even [shudder] emacs) on the host. Then each team member can deploy on the image and rest assured that, other than the code or configuration under development, they have the exact same deployment environment as everyone else.
In addition, vmware is a hog. This is to be expected, since it has an entire operating system to support, but I've found that for any real development, 1 gig of RAM is the absolute minimum. And if you have more than one image running at the same time, 1 gig is not enough. A fast processor is needed as well.
Still, for getting development off to a galloping start, vmware is a fantastic piece of software. Even with the downsides, it's worth a look.
July 13, 2005
Exchanging PostgreSQL for Oracle
I have a client who was building some commercial software on top of PostgreSQL. This plans to be a fairly high volume site, 1.8 million views/hour <=> 500 hits a second. Most of the software seemed to work just fine, but they had some issues with Postgres. Specifically, the backup was failing and we couldn't figure out why. Then, a few days ago, we saw this message:
ERROR: could not access status of transaction 1936028719
DETAIL: could not open file "/usr/local/postgres/data/pg_clog/0836": No such file or directory
After a bit of searching, I saw two threads suggesting fixes, which ranged from deleting the offending row to recreating the entire database.
I suggested these to my client, and he thought about it for a couple of days and came up with a solution not suggested on these threads: move to Oracle. Oracle, whose licensing and pricing has been famously opaque, now has a pricing list available online, with prices for the Standard Edition One and Enterprise Edition versions of their database, as well as other software they sell. And my client decided that he could stomach paying for Oracle, given:
1. The prices aren't too bad.
2. The amount of support and knowledgeable folks available for Oracle dwarfs the community of Postgres.
3. He just wants something to work. The value add of his company is in his service, not in the back end database (as long as it runs).
I can't fault him for his decision. PostgreSQL is full featured, was probably responsible for Oracle becoming more transparent and reasonable in pricing, and I've used it in the past, but he'd had enough. It's the same reason many folks have Macs or Windows when there is linux, which is a free tank that is "... invulnerable, and can drive across rocks and swamps at ninety miles an hour while getting a hundred miles to the gallon!".
I'll let you know how the migration goes.
June 20, 2005
Breaking WEP: a Flash Presentation
About two years ago, I wrote about how to secure your wireless network by changing your router password, your SSID, and turning on WEP. Regarding WEP, I wrote:
This is a 128 bit encryption protocol. It's not supposed to be very secure, but, as my friend said, it's like locking your car--a thief can still get in, but it might make it hard enough to not be worth their while.
Now, some folks have created a flash movie showing just how easy it is to break WEP. Interesting to watch, and has a thumping soundtrack to boot.
Via Sex, Drugs, and Unix.
June 17, 2005
Blogging and Legal Issues
Any new technology needs to fit into existing societal infrastructures, whether it's the printing press or the closed circuit TV system. Blogging is no different. I sometimes blog about what I get paid to work on, but always check with my employer first to make sure they're comfortable with it. Since I'm a developer, it's often general solutions to problems, and if need be, I omit any identifying information. Some folks take it farther..
Now, our good friends at the EFF have produced a legal guide for bloggers, which looks to be very useful, but is aimed only at those who live in the United States of America.
June 15, 2005
Search engine hits: a logfile analysis
I get most of my website hits on two posts: Yahoo Mail Problems and Using JAAS for Authentication and Authorization. It's common knowledge that if your business "does not rank in the top 20 spots on the major search engines, you might as well be in the millionth ranking spot", but that's apparently not strictly true for content. I looked at my webserver logs over a 42 hours stretch, when I got 125 hits from search engines, and looked at the start parameter, which generally indicates what page the results were on (0 is typically the first 10 results, 10 is the second 10, etc).
Here's the graph of my results:
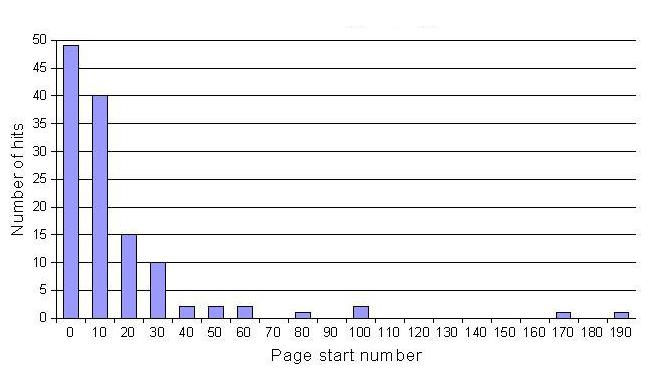
I have to admit I'm suprised by the number of hits beyond the first 20 results (columns 0 and 1)... 71.2% were from the first two pages, but that measn that 28.8% were from deeper in the search engine results. And someone went all the way to page 20--looking for a "servlet free mock exam" if you must know.
Interesting, for sure. Not that I'm claiming this is a long tail.
June 07, 2005
Useful Tools: wget
I remember writing a spidering program to verify url correctness, about six years ago. I used lwp and wrote threads and all kinds of good stuff. It marked me. Used to be, whenever I want to grab a chunk of html from a server, I scratch out a 30 line perl script. Now I have an alternative. wget (or should it be GNU wget?) is a fantastic way to spider sites. In fact, I just grabbed all the mp3s available here with this command:
wget -r -w 5 --random-wait http://www.turtleserviceslimited.org/jukebox.htm
The random wait is in there because I didn't want to overwhelm their servers or get locked out due to repeated, obviously nonhuman resource requests. Pretty cool little tool that can do a lot, as you can see from the options list.
June 06, 2005
IVR UI Guidelines
I was just complaining today to some friends that IVR systems (interactive voice recognition, or, the annoying female voice who 'answers' the phone and tries to direct you to the correct department when you call your credit card company) need some guidelines because it seems like every system does things just a little bit differently--enough to annoy the heck out of me. Well, lo and behold, google knows. Here is a paper on the topic and here's a coffee talk on the topic by a former coworker (today must be a day for references to former coworkers).
Some of my frustrations with IVR systems are due to the very market forces that drive companies to use them (making it hard to reach an operator helps when trying to cut labor costs) and some are due to limitations on audio as an information conveyance (typically, reading is quicker than listening).
New tech comic
Jut got an email from an old coworker who used to do some pretty great comic strips. (Nothing nationally syndicated that I know of.) He's started a new one, Bug Bash, that is 'updated weekly, technology-focused, and based loosely on my experiences at "a large northwest software company." '
Take a look...
May 26, 2005
Mail filtering
Here's a very interesting article for the sysdamins among us on how to fix the spam problem, at least for one site. The guy has received one million spams a day. Wow. It's worth struggling through the frames layout to find out how he fixes the problem.
May 11, 2005
Installing eRoom 7 on Windows XP Pro
This is a quick doc explaining how to install eRoom 7 on Windows XP Professional. It assumes that Windows XP Pro is installed, and you have the eRoom 7 setup program downloaded. This is based on the events of last week, but I believe I remembered everything.
1. Install IIS.
2. Make sure the install account has the 'Act As Part Of The Operating System' privilege. Do this by opening up your control panel (changing to the classic view if need be), double clicking Adminstrative Tools, then Local Security Policy, then expanding the Local Policies node, then clicking the User Rights Assignment node. Double click on 'Act as part of the operating system' (it's the 2nd entry on my list) and add the user that will be installing eRoom.
3. Restart.
4. Run the eRoom setup program. At the end, you'll get this message:
Exception number 0x80040707
Description: Dll function call crashed ISRT._DoSprintf
5. Re-register all your eRoom dlls by opening up a cmd window, cding to C:\Program Files\eRoom\eRoom Server\ and running
regsvr32.exe [dllname]
for each dll in that directory.
6. Run the eRoom MMC plugin: Start Menu, Run, "C:\Program Files\eRoom\eRoom Server\ERSAdmin.msc"
You should then be able to create a site via this screen.
May 05, 2005
Another use for Google maps
Why didn't I think of this first? Combining Google Maps and Craigslist, this site makes looking at rentals fun and easy. Wow!
Via OK/Cancel.
March 26, 2005
Metafor: Using English to create program scaffolding
Continuing the evolution of easier-to-use computer programming (a lineage which includes tools ranging from assembly language to the spreadsheet), Metafor is a way to build "the scaffolding for a program." This doesn't mean that programmers will be out of work, but such software sketching might help to bridge the gap between programmers and non-programmers, in the same way that VBA helped bridge that gap. (I believe that naked objects attacks a similar problem from a different angle.) This obviously has implications for novices and folks who don't understand formal problems as well. Via Roland Piquepaille's Technology Trends, which also has links to some interesting PDFs regarding the language.
However, as most business programmers know, the complicated part of developing software is not in writing the code, but in defining the problem. Depending on how intelligent the Metafor parser is, such tools may help non-technical users prototype their problems by writing sets of stories outlining what they want to achieve. This would have two benefits. In one case, there may be users who have tasks that should be automated by software, but who cannot afford a developer. While definitely not available at the present time, perhaps such story based software could create simple, yet sufficient, applications. In addition, software sketching, especially if a crude program was the result, could help the focus of larger software, making it easier (and cheaper!) to prototype a complicated business problem. In this way, when a developer meets with the business user, they aren't just discussing bullet points and static images, but an actual running program, however crude.
February 21, 2005
Looking for a job? RSS can help
Via buzzhit!, I found jobs.feedster.com. Now, I haven't found online methods to be as useful as some, but I don't deride it like others. It'll be interesting to see how useful jobs-via-RSS become, and I expect further cannibalization of newspaper revenues (as Tony mentions).
February 15, 2005
Article on XmlHttpRequest
XmlHttpRequest popped up on my radar a few months ago when Matt covered it. Back then, everyone and their brother was talking about Google Suggest. Haven't found time to play with it yet, but I like the idea of asynchronous url requests. There's lots of power there, not least the ability to make pull down lists dynamic without shipping everything to the browser or submitting a form via javascript.
I found a great tutorial on XmlHttpRequest by Drew McLellan, who also has a interesting blog. Browser based apps are getting better and better UIs, as Rands notices.
The Economist on Blogging
That bastion of free trade economics and British pithy humor has an article about corporate blogging: Face Value. It focuses on Scoble and Microsoft, but also mentions other bloggers, including Jonathan Schwarz.
There's defintely a fine line between blogging and revealing company secrets. Mark Jen certainly found that out. The quick, informal, personal nature of blogging, combined with its worldwide reach and googles cache, mean that it poses a new challenge to corporations who want to be 'on message'.
It also exposes a new risk for employees and contractors. I blog about all kinds of technologies, including some that I'm paid to use. At what point does the knowledge I gain from a client's project become mine, so that I can post about it? Or does it ever? (Obviously, trade secrets are off limits, but if I discover a better way to use Spring or a solution for a common struts exception, where's the line?) Those required NDAs can be quite chilling to freedom of expression and I have at least one friend who has essentially stopped blogging due to the precarious nature of his work.
February 07, 2005
Database links
I just discovered database links in Oracle. This is a very cool feature which essentially allows you to (nearly) transparently pull data from one Oracle database to another. Combined with a view, you can have a read only copy of production data, real time, without giving a user access to the production database directly.
Along with the above link, section 29 of the Database Administrator's Guide, Managing a Distributed Database, is useful. But I think you need an OTN account to view that link.
February 03, 2005
Networked J2ME Application article up at TSS
An article I wrote about Networked J2ME applications is up at TheServerSide.com. This was based on the talk I gave last year.
January 14, 2005
Options for connecting Tomcat and Apache
Many of the java web applications I've worked on run in the Tomcat servlet engine, fronted by an Apache web server. Valid reasons for wanting to run Apache in front of Tomcat are numerous and include increased clickstream statistics, Apache's ability to quickly and efficiently serve static content such as images, the ability to host other dynamic solutions like mod_perl and PHP, and Apache's support for SSL certificates. This last is especially important--any site with sensitive data (credit card information, for example) will usually have that data encrypted in transit, and SSL is the default manner in which to do so.
There are a number of different ways to deal with the Tomcat-Apache connection, in light of the concerns mentioned above:
Don't deal with the connection at all. Run Tomcat alone, responding on the typical http and https ports. This has some benefits; configuration is simpler and fewer software interfaces tends to mean fewer bugs. However, while the documentation on setting up Tomcat to respond to SSL traffic is adequate, Apache handling SSL is, in my experience, far more common. For better or worse, Apache is seen as faster, especially when when confronted with numeric challenges like encryption. Also, as of Jan 2005, Apache serves 70% of websites while Tomcat does not serve an appreciable amount of http traffic. If you're willing to pay, Netcraft has an SSL survey which might better illuminate the differences in SSL servers.
If, on the other hand, you choose to run some version of the Apache/Tomcat architecture, there are a few different options. mod_proxy, mod_proxy with mod_rewrite, and mod_jk all give you a way to manage the Tomcat-Apache connection.
mod_proxy, as its name suggests, proxies http traffic back and forth between Apache and Tomcat. It's easy to install, set up and understand. However, if you use this method, Apache will decrypt all SSL data and proxy it over http to Tomcat. (there may be a way to proxy SSL traffic to a different Tomcat port using mod_proxy--if so, I was unable to find the method.) That's fine if they're both running on the same box or in the same DMZ, the typical scenario. A byproduct of this method is that Tomcat has no means of knowing whether a particular request came in via secure or insecure means. If using a tool like the Struts SSL Extension, this can be an issue, since Tomcat needs such information to decide whether redirection is required. In addition, if any of the dynamic generation in Tomcat creates absolute links, issues may arise: Tomcat receives requests for localhost or some other hidden hostname (via request.getServerName()), rather than the request for the public host, whichApache has proxied, and may generate incorrect links.
Updated 1/16: You can pass through secure connections by placing the proxy directives in certain virtual hosts:
<VirtualHost _default_:80>
ProxyPass /tomcatapp http://localhost:8000/tomcatapp
ProxyPassReverse /tomcatapp http://localhost:8000/tomcatapp
</VirtualHost>
<VirtualHost _default_:443>
SSLProxyEngine On
ProxyPass /tomcatapp https://localhost:8443/tomcatapp
ProxyPassReverse /tomcatapp https://localhost:8443/tomcatapp
</VirtualHost>
This doesn't, however, address the getServerName issue.
Updated 1/17:
Looks like the Tomcat Proxy Howto can help you deal with the getServerName issue as well.
Another option is to run mod_proxy with mod_rewrite. Especially if the secure and insecure parts of the dynamic application are easily separable (for example, if the application was split into /secure/ and /normal/ chunks), mod_rewrite can be used to rewrite the links. If a user visits this url: https://www.example.com/application/secure and traverses a link to /application/normal, mod_rewrite can send them to http://www.example.com/application/normal/, thus sparing the server from the strain of serving pages needlessly encrypted.
mod_jk is the usual way to connect Apache and Tomcat. In this case, Tomcat listens on a different port and a piece of software known as a connector enables Apache to send the requests to Tomcat with more information than is possible with a simple proxy. For instance, certain variables are sent via the connector when Apache receives an SSL request. This allows Tomcat full knowledge of the state of the request, and makes using a tool like the aforementioned Struts SSL Extension possible. The documentation is good. However using mod_jk is not always the best choice; I've seen some performance issues with some versions of the software. You almost always have to build it yourself: binary releases of mod_jk are few and far between, I've rarely found the appropriate version for my version of Apache, and building mod_jk is confusing. (Even though mod_jk 1.2.8 provides an ant script, I ended up using the old 'configure/make/make install' process because I couldn't make the ant script work.)
In short, there are plenty of options for connecting Tomcat and Apache. In general, I'd start out using mod_jk, simply because that's the option that was built specifically to connect the two; mod_proxy doesn't provide quite the same level of integration.
December 24, 2004
ITConversations and business models
ITConversations is a great resource for audio conversations about technology. Doug Kaye, the owner/manager/executive assistant of IT Conversations, started a wiki conversation last month about that constant bugbear of all websites with free content: funding. Now, when you use 4.2 terrabytes a month of bandwidth, that problem is more intense than average; the conversation is still a worthwhile read for anyone trying to monetize their weblog or open content source.
December 07, 2004
Wireless application deployment solutions
It looks like there's another third party deployment solution being touted. Nokia is offering deployment services for distribution of wireless applications called Preminet Solution (found via Tom Yager). After viewing the hideous Flash presentation and browsing around the site (why oh why is the FAQ a PDF?) this solution appears to be very much like BREW, with perhaps a few more platforms supported (java and symbian are two that I've found so far). Apparently the service isn't launched yet, because when I click on the registration link, I see this:
"Please note that Preminet Solution has been announced, but it is not yet commercially launched. The Master Catalog registration opens once the commercial launch has been made."
For mass market applications, it may make sense to use this kind of service because the revenue lost by due to paying Nokia and the operators is offset by more buyers. However, if you have a targeted application, I'm not sure it's worthwhile. (It'll depend on the costs, which I wasn't able to find much out about.)
In addition, it looks like there's a purchasing application that needs to be downloaded or can be installed on new phones. I can't imagine users wanting to download another application just so they can buy a game, so widespread acceptance will probably have to wait until the client is distributed with new phones.
It'll be interesting to see how many operators pick up on this. It's another case of network effects (at least for application vendors); we'll see if Nokia can deliver the service needed to make Preminet the first choice for operators.
Anyway, wonder if this competitor is why I got an email from Qualcomm touting cheaper something or other? (Didn't really look at it, as I've written brew off until a J2ME bridge is available.)
December 05, 2004
Instant messaging and Yahoo!'s client
Like many folks, I've grown to depend on instant messaging (IM--it's also a verb, to IM is to 'instant message'), in the workplace. It's a fantastic technology, but two years ago, I turned up my nose at it. (Of course, 5 years ago, in a similar manner, I turned up my nose at a cell phone, and now I wouldn't be caught dead without it, so perhaps I'm not the best prognosticator.) What can it possibly offer that email can't? I'm going to examine it from the perspective of a software developer, since that's what I know; from that perspective, there are two main benefits IM offers that email doesn't, timeliness and presence:
I didn't think it was possible, but email can be too formal at times. When you have a question that needs to be answered right away or it becomes superfluous, IM is perfect. If it's a question about consistency of API or an area that you know the recipient knows much better than you, sometimes 30 seconds of their time can be worth 15 minutes of yours. Of course, there's a judgment call to be made; if you're constantly IMing questions about the API of java.lang.String, you risk breaking up the answerer's flow. However, used in moderation, it can greatly increase the communication between team members, especially when it's a distributed team.
Presence is also a huge benefit of most IM software. This means that you have a list of 'buddies' that the IM software monitors for you. When each signs on or signs off, you're made aware of that fact. This means that you can tell whether it's worthwhile calling someone with a deeper question, or if you should just compose an email. The technical details of presence are being codified at the IETF and I foresee this becoming more and more useful, because it's a non intrusive way for folks to manage their availability. It fulfills some of the same functions as a 'door closed/door opened' policy in an office, extending worldwide.
I use Yahoo IM because it fits my needs. Russell Beattie has recently written an overview of the main competitors and their clients, but technical geegaws like integration with music really don't matter all that much to me. Much more important are:
1. Does everyone I need to talk to have an account? How easy is it for them to get an account?
2. Does it have message archiving? How searchable are such archives?
3. How stable is the client?
That's about all I considered. I guess I let my contrarian streak speak too--I'm not a big fan of Microsoft, so I shyed away from Windows Messenger. There are some nice additional features, however. The ability to have a chat session, so that you can IM to more than one person at once, a la IRC, is nice. Grouping your buddies is great--each company I've consulted/contracted for has their own group in my IM client. I just discovered these instructions to put presence information on a web page. Combined with Maven and its intranet, or just put on any intranet page, this could be a useful tool for developers.
(I just read the Terms of Service for Yahoo, and I didn't see any prohibitions on commercial use of Yahoo Messenger; however, there are a couple of interesting clauses that anyone using it should be aware of. In section 3, I found out that Yahoo can terminate your account if your information is not kept up to date (not really enforceable, eh?). And in section 16, "[y]ou agree not to access the Service by any means other than through the interface that is provided by Yahoo! for use in accessing the Service." I wonder if that prohibits Trillian?)
One issue I have with the Yahoo client is the way status works. Presence is not a binary concept (there/not there); rather, it is broken down into various statuses--(not there/available/busy/out to lunch...). What I find myself doing is being very conscientious about changing my status from available to unavailable. However, I rarely remember to change back, which degrades the usefulness of the presence information. (If you have to ping someone over IM to see if they're actually there, it means you might as well not have status information at all.) I spent some time browsing the preferences of Yahoo's client, as well as googling, but didn't find any way to have the client pop up a message the first time I IM someone when my status is not available.
IM is very useful, and I can't imagine working without it now. I don't know what I'm going to do when Yahoo starts charging for it.
December 02, 2004
NextBus: a mobile poster child
I think that NextBus is a fantastic example of a mobile application. This website, which you can access via your mobile phone, tells you when the next bus, on a particular line, is coming. So, if you're out and about and have had a bit much to drink, or if you've just forgotten your bus schedule, you can visit their site and find out when the next bus will be at your stop. It's very useful.
This is almost a perfect application for a mobile phone. The information needed is very time sensitive and yet is easy to display on a mobile phone (no graphics or sophisticated data entry needed). NextBus has a great WAP interface, which probably displays well on almost every modern phone. The information is freely available (at least, information on when the next bus is supposed to arrive is freely available--and this is a good substitute for real time data).
And yet, there are profound flaws in this service. For one, it abandons a huge advantage by not knowing (or at least remembering) where I am. When I view the site to find out when the 203 is coming by next, I have to tell the site that I'm in Colorado, and then in Boulder. The website is a bit better, remembering that I am an RTD customer, but the website is a secondary feature for me--I'm much more interested in information delivered to my phone.
Also, as far as I can tell, the business model is lacking (and, no, I haven't examined their balance sheets). I don't know how NextBus is going to make money, other than extracting it from those wealthy organizations, the public transportation districts. (Yes, I'm trying to be sarcastic here.) They don't require me to sign in or pay anything for the use of their information, and I see no advertising.
So, a service that is almost perfect for the mobile web because of the nature of the information it conveys (textual and time sensitive) is flawed because it's not as useful as it could be and the business model is up in the air. I can't imagine a better poster child for the mobile Internet.
November 28, 2004
Syndication and blogs
I've tried to avoid self-referential blogging, if only becuase I'm not huge into navel staring. But, I just ran across an interesting blog: Wendyopolis, which is apparently associated with a Canadian magazine. Now, according to google, blogs are defined as:
"A blog is basically a journal that is available on the web. The activity of updating a blog is "blogging" and someone who keeps a blog is a "blogger." Blogs are typically updated daily using software that allows people with little or no technical background to update and maintain the blog.
Postings on a blog are almost always arranged in chronological order with the most recent additions featured most prominently."
(From the Glossary of Internet Terms)
However, I'd argue that there are several fundamental characteristics of a blog:
1. Date oriented format--"most recent additions featured most prominently."
2. Informal, or less formal, writing style.
3. Personal voice--a reader can associate a blog with a person or persons.
4. Syndicatability--the author(s) provide RSS or Atom feeds. The feeds may be crippled in some way, but they are available.
5. Permalinks--postings are always available via an unchanging URL.
I can't really think of any other salient characteristics. But the reason for this post is that Wendyopolis, which looks to be a very interesting weblog, doesn't have #4. In some ways, that's the most important feature, because it allows me to pull content of interest to one location, rather than visit sites.
I've written about this before, so I won't beat a dead horse. Suffice it to say that, while Wendyopolis may speak to me right now, the chances of me ever visiting that blog ever again are nil, because of the lack of syndication. Sad, really.
September 20, 2004
Open Books at O'Reilly
I'm always on the lookout for interesting content on the internet. I just stumbled across Free as in Freedom, an account of Richard Stallman, which is published under the umbrella of the Open Books Project.
September 15, 2004
Relearning the joys of DocBook
I remember the first time I looked at Simple DocBook. I have always enjoyed compiling my writing--I wrote my senior thesis using LaTeX. When I found DocBook, I was hooked--it was easier to use and understand than any of the TeX derivatives, and the Simplified grammar had just what I needed for technical documentation. I used it to write my JAAS article.
But, I remember it being a huge hassle to set up. You had to download openjade, compile it on some systems, set up some environment variables, point to certain configuration files and in general do quite a bit of fiddling. I grew so exasperated that I didn't even setup the XML to PDF conversion, just the XML to HTML.
Well, I went back a few weeks ago, and found things had improved greatly. With the help of this document explaining how to set DocBook up on Windows, I was able to generate PDF and HTML files quickly. In fact, with the DocBook XSL transformations and the power of FOP, turning a Simplified DocBook article into a snazzy looking PDF file is as simple as this (stolen from here):
java -cp "C:\Programs\java\fop.jar; \
C:\Programs\java\batik.jar;C:\Programs\java\jimi-1.0.jar; \
C:\Programs\java\xalan.jar; C:\Programs\java\xerces.jar; \
C:\Programs\java\logkit-1.0b4.jar;C:\Programs\java\avalon-framework-4.0.jar" \org.apache.fop.apps.Fop -xsl \ "C:\user\default\xml\stylesheets\docbook-xsl-1.45\fo\docbook.xsl" \ -xml test.xml -pdf test.pdf
Wrap that up in a shell script, and you have a javac for dcuments.
September 14, 2004
Abstractions, Climbing and Coding
I vividly remember a conversation I had in the late 1990s with a friend in college. He was an old school traditional rock climber; he was born and raised in Grand Teton National Park. We were discussing technology and the changes it wreaks on activities, particularly climbing. He was talking about sport climbing. (For those of you not in the know, there are several different types of outdoor rock climbing. The two I'll be referring to today are sport climbing and traditional, or trad, climbing. Sport climbers clip existing protection to ensure their safety; traditional climbers insert their own protection gear into cracks.) He was not bagging on sport climbing, but was explaining to me how it opened up the sport of climbing. A rock climber did not need to spend as much money acquiring equipment nor as much time learning to use protection safely. Instead, with sport climbing, one could focus on the act of climbing.
At that moment it struck me that what he was saying was applicable to HTML generation tools (among many, many other things). During that period, I was just becoming aware of some of the WYSIWYG tools available for generating HTML (remember, in the late 1990s, the web was still gaining momentum; I'm not even sure MS Word had 'Save As HTML' until Word 97). Just like trad versus sport, there was an obvious trade off to be made between hand coding HTML and using a tool to generate it. The tool saved the user time, but acted as an abstraction layer, clouding the user's understanding of what was actually happening. In other words, when I coded HTML from hand, I understood everything that was going on. On the other hand, when I used a tool, I was able to make snazzier pages, but didn't understand what was happening. Let's just repeat thatI was able to do something and have it work, all without understanding why it worked! How powerful is that?
This trend, towards making complicated things easier happens all the time. After all, the first cars were difficult to start, requiring hand cranking, but now I just get in the car and turn the key. This abstraction process is well and good, as long as we realize it is happening and are willing to accept the costs. For there are costs, in climbing, but also in software. Joel has something to say on this topic. I saw an example of this cost myself a few months ago, when Tomcat was not behaving as I expected, and I had to work around an abstraction that had failed. I also saw a benefit to this process of abstraction when I was right out of school. In 1999, there was not the body of frameworks and best practices that currently exist. There was a lot of invention from scratch. I saw a shopping cart get built, and wrote a user authentication and authorization system myself. These were good experiences, and it was much easier to support this software, since it was understood from the ground up by the authors. But, it was hugely expensive as well.
In climbing terms, I saw this trade off recently when I took a friend (a much better climber than I) trad climbing. She led a pitch far below her climbing level, and yet was twigged out by the need to place her own protection. I imagine that's exactly how I would feel were I required to fix my brakes or debug a compiler. Dropping down to a lower abstraction takes energy, time, and sometimes money. Since you only have a finite amount of time, you need to decide at what abstraction level you want to sit. Of course, this varies depending the context; when you're working, the abstraction level of Visual Basic may be just fine, because you just need to get this small application written (though you shouldn't expect such an application to scale to multiple users). When you're climbing, you may decide that you need to dig down to the trad level of abstraction in order to go the places you want to go.
I recently read an interview with Richard Rossiter, who has written some of the canonical guidebooks for front range area climbing. When asked where he thought "climbing was going" Rossiter replied: "My guess is that rock climbing will go toward safety and predictability as more and more people get involved. In other words, sport climbing is here to stay and will only get bigger...." A wise prediction; analogous to my prediction that sometimes understanding the nuts and bolts of an application simply isn't necessary. I sympathize. I wouldn't have wanted to go climbing with hobnail boots and manila ropes, as they did in the old days; nor would I have wanted to have to write my own compiler, as many did in the 1960s. And, as my college friend pointed out, sport climbing does make climbing in general safer and more accessible; you don't have to invest a ton of time learning how to fiddle with equipment that will save your life. At the same time, unless you are one of the few who places bolts, you are trusting someone else's ability to place equipment that will save your life. Just like I've trusted DreamWeaver to create HTML that's readable by browsersif it does not, and I don't know HTML, I have few options.
Note, though, that it is silly for folks who sit at one level of abstraction to denigrate folks at another. After all, what is the real difference between someone using a compiler and someone using DreamWeaver? They're both trying to get something done, using something that they probably don't understand. (And if you understand compilers, do you understand chip design? How about photo-lithography? Quantum mechanics? Everyone uses things they don't understand at some level.)
It is important, however, to realize that even if you are using a higher abstraction level, there's a certain richness and joy that can't be achieved unless you're at the lower level. (The opposite is true as wellI'd hate to deal with strings instead of classes all the time; sport climbing frees me to enjoy movement on the rock.) Lower levels tend to be more complicated (that's what abstraction doeshides complex 'stuff' behind a veneer of simplicity), so fewer folks enjoy the benefits of, say, trad climbing or compiler design. Again, depending on context, it may be well worth your while to dip down and see whether an activity like climbing or coding can be made more fulfilling by attacking it at a lower level. You'll possibly learn a new skill, which, in the computer world can be a career helper, and in the climbing world may save your life at some time. You'll also probably appreciate the higher level activities if and when you head back to that level, because you'll have an understanding of the mental and temporal savings that the abstraction provides.
September 10, 2004
Slackware to the rescue
I bought a new Windows laptop computer about nine months ago, to replace my linux desktop that I purchased in 2000. Yesterday, I needed to check to see if I had a file or two on the old desktop computer, but I hadn't logged in for eight months; I had no idea what my password was. Now, I should have a root/boot disk set, even though floppy disks are going the way of cursive. But I didn't. Instead, I had the slackware installation disks from my first venture into linux: a IBM PS/2, with 60 meg of hard drive space, in 1997. I was able to use those disks to load a working, if spartan, linux system into RAM. Then, I mounted the boot partition and used sed (vi being unavailable) to edit the shadow file:
sed 's/root:[^:]*:/root::/' shadow > shadow.new
mv shadow.new shadow
Unmount the partition, reboot, pop the floppy out, and I'm in to find that pesky file. As far as I know, those slackware install disks are the oldest bit of software that I own that still is useful.
September 02, 2004
New approach to comment spam
Well, after ignoring my blog for a week, and dealing with 100+ comment spams, I'm taking a new tack. I'm not going to rename my comments.cgi script anymore, as that seems to have become less effective.
Instead, I'm closing all comments on any older entry that doesn't have at least 2 comments. When I go through and delete any comment spam, I just close the entry. This seems to have worked, as I've dealt with 2-3 comment spams in the last week, rather than 10+.
I've also considered writing a bit of perl to browse through Movable Types DBM database to ease the removal of 'tramadol' entries (rather than clicking my way to carpal tunnel). We'll see.
(I don't even know what's involved in using MT-Blacklist. Not sure if the return would be worth the effort for my single blog installation.)
Back to google
So, the fundamental browser feature I use the most is this set of keystrokes:
* cntrl-T--open a new tab
* g search term--to search for "search term"
(I set up g so the keyword expands and points to a search engine.)
Periodically, I'll hear of a new search engine--a google killer. And I'll switch my bookmark so that 'g' points to the new search engine. I've tried AltaVista, Teoma and, lately, IceRocket. Yet, I always return to Google. The others have some nice features--IceRocket shows you images of the pages--and the search results are similar enough. What keeps me coming back to google is the speed of the result set delivery. I guess my attention span has just plain withered.
Anyone else have a google killer I should try?
July 01, 2004
An open letter to Climbing magazine
Here's a letter to Climbing magazine. I'm posting it here because I think that the lessons Climbing is learning, especially regarding the Internet, are relevant to every print magazine.
--------------------
I just wanted to address some of the issues raised in the Climbing July 2004 Editorial, where you mention that you've cut back on advertising as well as touching on the threat to Climbing from website forums. First off, I wanted to congratulate you on adding more content. If you're in the business of delivering readers to advertisers you want to make sure that the readers are there. It doesn't matter how pretty the ads are--Climbing is read for the content. I'm sure it's a delicate balance between (expensive) content that readers love and (paid) advertisements which readers don't love; I wish you the best in finding that balance.
I also wanted to address forums, and the Internet in general. I believe that websites and email lists are fantastic resources for finding beta, discussing local issues, and distributing breaking news. Perhaps climbing magazines fulfilled that need years ago, but the cost efficiencies of the Internet, especially when amateurs provide free content, can be hard to beat. But, guess what? I don't read Climbing for beta, local issues, or breaking news. I read Climbing for the deliberate, beautiful articles and images. This level of reporting, in-depth and up-close, is difficult to find on the web. Climbing should continue to play to the strengths of a printed magazine--quality, thoughtful, deliberate articles and images; don't ignore breaking news, but realize that's not the primary reason subscribers read it. I don't see how any magazine can compete with the interactivity of the Internet, so if Climbing wants to foster community, perhaps it should run a mailing list, or monitor rec.climbing (and perhaps print some of the choice comments). I see you do run a message board on climbing.com--there doesn't look to be much activity--perhaps you should promote it in the magazine?
Now for some concrete suggestions for improvement. One of my favorite sections in Climbing is 'Tech Tips.' I've noticed this section on the website--that's great. But, since this information is timeless, and I've only been a subscriber for 3 years, I was wondering if you could reprint older Tech Tips, to add cheap, useful content to Climbing. Also, I understand the heavy emphasis on the modern top climbers--these are folks that have interesting, compelling stories to tell, which are interesting around the world. Still, it'd be nice to see 'normal' climbers profiled as well, since most of us will never make a living climbing nor establish 5.15 routes, but all climbers have stories to share. And a final suggestion: target content based on who reads your magazine. Don't use just a web survey, as that will be heavily tilted in favor of the folks who visit your website (sometimes no data is better than skewed data). Instead find out what kind of climbers read your magazine in a number of ways: a web survey, a small survey on subscription cards, paper surveys at events where Climbing has presence, etc. This demographic data will let you know if you should focus on the latest sick highball problem, the latest sick gritstone headpoint or the latest sick alpine ascent.
Finally, thanks for printing a magazine worth caring about.
--------------------
June 26, 2004
Friendster re-written in PHP
Friendster is still alive and kicking, and according to
I check in, periodically, to Friendster to see if anyone new has joined, or added a new picture, or come up with a new catchy slogan for themselves. When I joined, it was daily, now it's monthly. One of the things that detracted from the experience was the speed of the site. It was sloooow. Well, they've dealt with that--it's now a peppy site (at least on Saturday morning). And it appears that one of the ways they did this was to switch from JSP to PHP. Wow. (Some folks noticed a while ago.) I wasn't able to find any references comparing the relative speed of PHP and JSP, but I certainly appreciate Friendster's new responsiveness.
June 15, 2004
Symlinks and shortcuts and Apache
So, I'm helping install Apache on a friend's computer. He's running Windows XP SP1, and Apache has a very nice page describing how to install on Windows. A few issues did arise, however.
1. I encountered the following error message on the initial startup of the web server:
[Tue Jun 15 23:09:11 2004] [error] (OS 10038)An operation was attempted on something that is not a socket. : Child 4672: Encountered too many errors accepting client connections. Possible causes: dynamic address renewal, or incompatible VPN or firewall software. Try using the Win32DisableAcceptEx directive.
I read a few posts online that suggested I could just follow the instructions--I did and just added the Win32DisableAcceptEx directive to the bottom of the httpd.conf file. A restart, and now localhost shows up in a web browser.
2. Configuration issues: My friend also has a firewall on his computer (good idea). I had to configure the firewall to allow Apache to receive packets, and respond to them. Also, I had to configure the gateway (my friend shares a few computers behind one fast internet connection) to forward the port that external clients can request information from to the computer on which Apache was running. Voila, now I can view the default index.html page using his IP address.
3. However, the biggest hurdle is yet to come. My friend wants to server some files off one of his hard drives (a different one than Apache is installed upon). No problem on unix, just create a symlink. On windows, I can use a shortcut, right? Just like a symlink, they "...can point to a file on your computer or a file on a network server."
Well, not quite. Shortcuts have a .lnk extension, and Apache doesn't know how to deal with that, other than to serve it up as a file. I did a fair bit of searching, but the only thing I found on dealing with this issue was this link which basically says you should just reconfigure Apache to have its DocRoot be the directory which contains whatever files you'd like to serve up. Ugh.
However, the best solution is to create an Alias (which has helped me in the past) to the directories you're interested in serving up. And now my friend has Apache, installed properly as a service, to play around with as well.
May 28, 2004
Death marchs and Don Quixote
I just finished watching 'Lost In La Mancha' which chronicles Terry Gilliam's attempt to film his version of the story of Don Quixote, 'The Man Who Killed Don Quixote'. (More reviews here.) The attempt failed, though there was a postscript that indicated that Gilliam was trying again. (An aside: not the best date movie.)
It was interesting to watch the perspective of the team start upbeat and slowly descend into despair. There were many reasons the filming failed, but what was most fascinating is that it was a death march project that just happened to take place in the sphere of film.
Of course there were certain 'acts of God' that contributed to the failure, but there always are difficulties beyond control. What's more interesting to me is the disasters that could have been planned for. Read through some of the aspects of 'Lost In La Mancha' and see if you recognize any (plenty of spoilers, so don't read if you want to watch the movie):
1. Gilliam tried to create a $60 million film on a $32.1 million dollar budget. He actually smiles while saying words to this effect!
2. Not all key players present during planning. In pre-production, none of the actors are able to schedule time to rehearse, partly because they all took pay cuts to make this movie (see point 1), partly because they were all busy.
3. Tight timelines. Due to money and scheduling, every day of filming was very carefully planned out; any problems on early days required changes to the entire schedule.
4. A visionary architect wasn't willing to compromise. Gilliam is well known for his mind-blowing films (Twelve Monkeys, Brazil) and had been working on this movie in his mind for decades. This led to perfectionism, which, given the tight timelines and lack of money, wasn't always the right use of resources. Addtitionally, Gilliam had a lackadaisical methodology: he mentions several times that his philosophy is 'just shoot film and it will work out.' That sounds freakishly similar to 'just start coding and everything will be fine.'
5. Project history worked against success. This is one of the most interesting points--there were really two kinds of project history present. Film versions of 'Don Quixote' have a checkered past--Orson Welles tried for years to make a version, even continuing to film beyond his Don Quixote dying. And Gilliam has had at least one bomb--The Adventures of Baron Munchausen, a box office failure which haunted him for years. In both of these cases, there past actions cast a shadow over the present, affecting morale of the team.
6. When problems arose, the producers didn't trust the technical staff (the directors). In particular, when weather struck, the directors wanted to allow the team to regroup, whereas the producers, because of points 1 and 3, wanted to film. Strife at the top never helps a project.
7. The equipment and setting was not optimal. Due to, I'm guessing, point 1, the outside scenes are set in a location next to a NATO air base, where jets will be flying overhead ('only for an hour a day' according to the first assistant director). The last sound stage in Madrid is reserved--it turns out to be a simple warehouse with awful acoustics.
And then there were some factors that simply were out of the blue. These included some bad weather and the illness of the actor playing Don Quixote. These were what pushed the film over the edge--but it wouldn't have been on the edge if not for the other factors above. And you can also see that factors snowball on each other--timelines are tight because actors aren't around; trust between team members is lost because of money and time issues.
It was like watching a train wreck in slow motion, but it was also illuminating to see that the lessons of project management not only are ignored in the software development, but also in film. Misery loves company.
May 14, 2004
vi keybindings for Word
Well, someone's finally done it. William Tan has put together a set of vi key bindings for Microsoft Word. (Thanks for the pointer, NTK!) I just downloaded and installed it, and thought I'd mention a few things.
1. The author mentions the instability ("alpha" nature) of the code. I haven't run it long, but I get quite a few "Error 5346" and "Error 4198" messages. I'm no VB expert (nor even a newbie) so I have no idea what those mean. It didn't seem to affect the document I was editing.
2. Installing the .dot file exposed some weirdness. The default location where you're supposed to put these files (on WinXP, with Word 2003) is c:\Documents And Settings\Username\Application Data\Microsoft\Word\Startup\. Both the Application Data and Microsoft directories in the above path were hidden from Windows Explorer and the dir command in the shell, but you can cd to them.
The easiest way to install the .dot file is to open up Word, navigate via menus: Tools / Options / File Locations / Startup. Click the modify button, which brings up a file dialog box. Then drag the .dot file to that dialog box.
All in all, I'm glad someone has done this. Now, if only they'd do it for an IDE editor. Errm, I mean a free IDE--I know Visual Slickedit has a killer vi emulation mode. Yes, I know about Vimulator for jEdit, but the author's language ("This plugin is in the early stages of implementation and does not yet provide a consistent or reliable VI-style interface."), along with the fact it was last released in 2002, scared me away. Actually, it looks like there is one available for Eclipse: viPlugin.
Regardless, a very cool hack. Thanks, William.
May 10, 2004
What the heck is Flash good for?
Flash is a fairly pervasive rich client framework for web applications. Some folks have issues with it. I've seen plenty of examples of that; the Bonnaroo site is an example of how Flash . Some folks think it's the future of the internet. I like it, when it's used for good purpose, and I thought I'd share a few of my favorite flash applications:
1. Ishkur's guide to electronic music has an annoying intro, but after that, it's pure gold. Mapping the transitions and transformations of electronic music, complete with commentary and sample tracks, I can't imagine a better way to get familiar with musical genres and while away some time.
2. They Rule is an application that explores the web of relationships among directors on boards of public companies. Using images, it's much easier to see the interconnectedness of the boards.
3. A couple of short animated pieces: Teen Girl Squad follows the (amateurly drawn) exploits of, well, a set of four teenage girls, and a cute movie about love (originally from http://students.washington.edu/k1/bin/Ddautta_01_masK.swf).
Of course, these all beg the question: what is a rich client good for (other than cool movies)? When is it appropriate to use Flash (or ActiveX, or XUL) rather than plain old (D)HTML? I wish I knew the answer, but it seems to me that there are a couple of guidelines.
1. How complicated is the data? And how complicated is the representation of that data? The more complicated, the more you should lean towards rich clients. I can't imagine the electronic guide to music being half as effective if it was done in html.
2. How savvy are your users? This cuts both ways--if the users aren't savvy, then the browser may be a comfortable, familiar experience. However, sometimes rich clients can 'act smarter' and make for a better user experience.
3. How large is your userbase? The larger, the more you should tend towards a thin, pervasive client like the browser, since that will ease deployment issues.
I used to think Flash was unabatedly evil, but I'm now convinced that, in some cases, it really makes a lot of sense.
May 03, 2004
Will RSS clog the web?
I'm in favor of promoting the use of RSS in many aspects of information management. However, a recent wired article asks: will RSS clog the web? I'm not worried much. Why?
1. High traffic sites like slashdot are already protecting themselves. I was testing my RSS aggregator, and hit slashdot's RSS feed several times in a minute. I was surprised to get back a message to the effect of 'You've hit Slashdot too many times in the last day. Please refrain from hitting the site more than once an hour' (not the exact wording, and I can't seem to get the error message now). It makes perfect sense for them to throttle down the hits from programs--they aren't getting the same amount of ad revenue from RSS readers.
2. The Wired article makes reference to "many bloggers" who put most of their entries' content in their RSS feed, which "allow[s] users to read ... entries in whole without visiting" the original site. This is a bit of a straw man. If you're having bandwidth issues because of automated requests, decrease the size of the file that's being requested by not putting every entry into your RSS feed.
3. The article also mentions polling frequency--30 minutes or less. I too used to poll at roughly this frequency--every hour, on the 44 minute mark. Then, it struck me--I usually read my feeds once, or maybe twice, a day. And rarely do I read any articles between midnight and 8am. I tweaked my aggregator to check for new entries every three hours between 8am and midnight. There's no reason to do otherwise with the news stories and blog entries that are most of the current RSS content. Now, if you're using RSS to get stock prices, then you'll probably want more frequent updates. Hopefully, your aggregator allows different frequencies for updating; Newsgator 1.1 does.
This comes back to the old push vs. pull debate. I like RSS because I don't have to give out me email address (or update it, or deal with the unwanted newsletters in my inbox) and because it lets me automatically keep track of what people are saying. I think there's definitely room for abuse with RSS spiders, just like with any other automated system; after all "a computer lets you make more mistakes faster than any invention in human history -- with the possible exceptions of hand guns and tequila.". I don't think RSS will clog the web--it's just going through some growing pains.
April 09, 2004
Three tech tips
Here are three items that I've found useful in the past, but aren't worth an individual post because of their triviality.
1. Sometimes file archives are only available in .zip format. There are unix programs out there that can unzip such archives, and linux often ships with one. But sometimes it's not installed. Lately, I'm almost always doing some kind of java development, in which case, you can use the jar command to extract the archive.
2. I generate an html page of all my rss feeds, using a custom perl hack (I wouldn't go so far as to term it a script). (No newsgator for me! Did I mention I still use pine for email?) This can produce quite a big file, since I'm querying around 80 feeds. In an effort to reduce my bandwidth, which I pay for, I now gzip my rss feeds page, using CPU that I don't pay for (well, not directly). And, while gzip may not be the most efficient of compressors, files in gzipped format can be transparently read in all the browsers I cared to test: Mozilla, Firefox, IE, and even lynx.
3. Sometimes you just want the data from a mysql query in an easy format that you can pull into a spreadsheet and manipulate further. In the past, I would have written a quick perl script, using DBI, but after investigating the client options, I found another way. mysql -u user -B -ppass -e 'select * from my_data' databasename gives you nice tab delimited output. I've used this with the mysql 4 client; since I couldn't track down the mysql 3 manual, I'm not clear what version of the mysql client supports these features.
April 07, 2004
The perfect 404 page
We've all been frustrated when we hit an outdated link. How many sites actually use a link checker? Meri has a link to an article about the perfect 404 page. I'd like to submit BCN's 404 page as the most helpful one I've ever seen. This is more fun, but perhaps less helpful.
March 31, 2004
Firefox customization
Firefox, the lightweight browser based on Mozilla, has been garnering quite a bit of attention lately. I've been a Mozilla user since 0.5, but only use the browser component, so I thought I'd give Firefox a try. It works great, and is very similar to IE (by design, no doubt). But browsing is a habit of mine, and, like anybody else, I don't like to change my habits. Luckily, it was easy to change Firefox to fit my needs.
1. Have the search bar respond to my shortcuts (i for google images, g for google search, q for qwestdex search). This was no different than setting it up for Mozilla.
2. Firefox by default saves form entries. I don't like that--it's the paranoid in me. Easily changed: go to Tools / Options / Privacy / Saved Form Information and deselect the "Save information..." checkbox.
3. Firefox blithely closes a window when there's more than one tab open. Wow! I don't like that at all--Mozilla gives me a warning and 99% of the time, I was aiming at the wrong window or had forgotten that I had multiple tabs open. Feedster handed me this post so I knew I wasn't alone; a bit of searching on MozDev turned up this handy extension: tab warning. Installing this was a snap, and now my browsing experience is back to what I expected.
One problem I haven't figured out how to fix: in Mozilla, when you open a link in a new tab, the new tab gains focus. In Firefox, the old tab remains in front.
March 27, 2004
Spamorama
I just ran across one of the most virulent pieces of weblog spam I've ever seen. It was an innocuous comment: 'please help with my website...' and the URL wasn't ostentatiously bad:
pseudobreccia60 DOT tripod DOT com DOT ve (please don't visit this site!)
pseudobreccia, in case you're wondering, is a kind of rock. ve is the Venezuelan country code. tripod DOT com DOT ve points to ns4.hotwired.com as its authoritative name server. The comment wasn't blatantly off topic. So, I wasn't super suspicious of the site.
Being a bit curious, I visited it. What you get is some kind of flash application. It seems innocent enough, just an ad and an under construction sign. Viewing source shows you nothing, but every time you close the window, or change the location in the address bar, it pops up a new window with the same URL in it (I ended up having to shut the browser down entirely via the Process Manager before it would go away). But, the payload is a periodical full size window pop up with advertisements for, what else, p0rn. Shocking, I know. But the persistance of the app was amazing. I almost wish I had a flash decompiler just to take a look at what it was doing.
I was doing all this in Mozilla--I can't imagine what it tries to do to Internet Explorer (sets up itself as your homepage, adds itself to your favorites) and I don't want to find out.
March 07, 2004
The people's voice
Tim Bray points out Radio Vox Populi which is a really cool idea:
weblogs + web crawler + text-to-speech + mp3 streaming = talk radio for everyone.
Of course it could do with some filtering, or categorization, but it's a cool idea. It actually jives with an idea I've had for a long time, which is to use text-to-speech, perhaps Festival, to burn cds of Project Gutenberg to create cheap books on cd (oh, should I listen to Boy Scouts on Motorcycles, by G. Harvey Ralphson or Armenian Literature, by Anonymous today?). That'd be cool, if you can handle listening to a robot voice.
February 26, 2004
An IM application server
I've written before about IM in the workplace. It's becoming more and more prevalent, and other people have noticed this as well. IM is something that's easy to use, and gives you the immediate response of the phone without be nearly as intrusive.
Now, in the past, using IRC, it was relatively easy to have a program, or bot, that would listen to conversations, or that you could ask questions of. They were dumb, but they worked. In the world of IM, I wasn't aware of any easy way to do this. However, browsing freshmeat yesterday I discovered an easy way to write IM applications.
It's called the SDBA Revolution Instant Messaging Application Server and building IM applications is fantastically easy if you use this perl framework. I was able to download it, and build a simple application in about 30 minutes. And that includes signing up for the usernames from AOL. It uses a perlish syntax and doesn't support extremely complicated applications, but does offer enough to be useful. If you can code a php website, you can build an IM application. The author even provides six or so sample applications, including a database interface (scary!). The only issues I found with the IM app server were:
1. It doesn't support Yahoo! That's because the Yahoo! IM perl module has been unmaintained since the last Yahoo! protocol update.
2. I'm not sure of the legality of using a bot on a public service like AIM, MSN, or Yahoo!. Violations of these license agreements happen all the time, but, if you're a stickler for those darn license agreements, this application server appears to work with Jabber.
Just goes to show you that 30 minutes a week browsing freshmeat or SourceForge will almost never be wasted. A bit of slack to do this will probably pay off in the long run.
February 15, 2004
Moving a Paradox application to PostgreSQL
I have a client that has an existing Paradox database. This database is used to keep track of various aspects of their customers, and is based on a database system I originally wrote on top of Notebook, so I'm afraid I have to take credit for all of the design flaws present in the application. This system was a single user Paradox database, with the client portion of Paradox installed on every computer and the working directory set to a shared drive location. It wasn't a large system; the biggest table had about 10k records.
This system had worked for them for years, but recently they'd decided they needed a bit more insight into their customer base. Expanding the role of this database was going to allow them to do that, but the current setup was flawed. Paradox (version 10) often crashed, and only one user could be in at a time. I took a look at the system and decided that moving to a real client server database would be a good move. This would also allow them to move to a different client if they ever decided to get Access installed, or possibly a local web server. This document attempts to detail the issues I ran into and the steps I followed to enable a legacy Paradox application to communicate with a modern RDBMS.
I chose PostgreSQL as the DBMS for the back end. I wasn't aware at the time that MySQL was recently freed for commercial use, but I still would have chosen PostgreSQL because of the larger feature set. The client had a Windows 2000 server; we discussed considered installing a Linux box in addition, but the new hardware costs and increased maintenance risk led me to install PostgreSQL on the Windows 2000 server. With Cygwin's installer, it was an easy task. I followed the documentation to get the database up and running after Cygwin installed it. They even have directions for installing the database as a Windows service (it's in the documentation with the install), but since this was going to be a low use installation, I skipped that step.
After PostgreSQL was up and running, I had to make sure that the clients could access it. This consisted of three steps:
1. Make sure that clients on the network could access the database. I had to edit the pg_hba.conf file and start PostgreSQL with the -i switch. The client's computers are all behind a firewall, so I set up the database to accept any connections from that local network without a password.
2. Install the PostgreSQL ODBC driver and create a system ODBC DSN (link is for creating an Access db, but it's a similar process) for the new database on each computer.
3. Creating an alias in Paradox that pointed to the ODBC DSN.
Once these steps are done, I was able to query a test table that I had created in the PostgreSQL database. One thing that I learned quickly was that two different computers could indeed access PostgreSQL via the Paradox front end. However, in order to see each others changes to the database, I had to hit cntrl-F3, which refreshed from the server.
The next step was to move the data over. There are several useful articles about moving databases from other RDBMS to PostgreSQL here, but I used pxtools to output the data to plain text files. I then spent several days cleansing the data, using vi. I:
1. Exported table names were in mixed case; I converted them to lower case. PG handles mixed case, but only with " around the table names, I believe.
2. Tried to deal with a complication from the database structure. I had designed it with two major tables, which shared a primary key. The client had been editing the primary key, and this created a new row in the database for one of the tables, but not the other. In the end, matching these up became too difficult, and the old data (older than a couple of years) was just written off.
3. Removed some of the unused columns in the database.
4. Added constraints (mostly not null) and foreign key relationships to the tables. While these had existed in the previous application, they weren't captured in the export.
Then I changed the data access forms to point to the new database. The first thing I did was copy each of the data access forms, so that the original forms would still work with the original database. Most of the forms were very simple to portthey were just lookup tables. I found the automatic form generator to be very helpful here, as I added a few new lookup tables and this quickly generated the needed update/insert forms.
However, I did have one customized form that caused problems. It did inserts into three different tables. After the database rationalization, it only inserted into two, but that was still an issue. Paradox needed a value for the insert into each table (one because it was a primary key, the other because it was a foreign key). I couldn't figure out how to have Paradox send the key to the both inserts without writing custom code. So, that's what I did. I added code to insert first into the table for which the value was a primary key, and later to insert the value into the table for which it was a foreign key. It wasn't a pretty solution, and I think the correct answer was to combine the two tables, but that wasn't an option due to time and money constraints. I also made heavy use of the self.dataSource technique to keep lists limited to known values.
After moving the forms over, I had to move one or two queries over (mostly query by examples, qbes, which generated useful tables), but that was relatively straight forward; this was a helpful article regarding setting up some more complicated qbes. Also, I found a few good resources here and here.
I also updated a few documents that referenced the old system, and tried to put instructions for using the new system onto the forms that users would use to enter data. I moved the original database to a different directory on the shared drive, and had the client start using the new one. After a bit of adjusting to small user interface issues, as well as the idea that more than one user could use the database, the client was happy with the results.
February 13, 2004
Turn off the download manager in Mozilla
I hate the download manager that Mozilla turns on by default. It's another window you have to Alt - Tab through, and it rarely has useful information for me. Granted, if I was on a modem, or downloaded files often, it might be more useful. But as it is, 90% of the time that it pops open, I don't even look at it until the download is done. In fact, I can't think of a single time when having the download manager has been useful for me, even though it's high on other people's lists of cool features in Mozilla (or, in this case, Firefox).
Luckily, you can turn it off in Mozilla 1.6 (I haven't tried in earlier versions). Go to edit / preferences / download / ... and choose the behavior you want when downloading files.
February 12, 2004
Windows frustrations
I'm reading Hackers by Steven Levy right now. This book is about the first people to really program computers with enthusiasm and an eye towards some of the anarchic possibilities of the machine. And the obstacles they overcame were tremendous. Writing entire video games in assembly language, re-implementing FORTRAN for different platforms (heck, writing anything in FORTRAN at all is a trial), working with computers the size of entire building floors, dealing with the existing IBM priesthood... There were plenty of obstacles to getting work done with a computer back then.
And, there still are, I have to say. I'm currently writing this from my first laptop ever. I love it. The mobility, the freedom, especially when combined with a wireless network card. This computer came with Windows XP and I plan to leave windows on this box, primarily so that I can do more J2ME development.
Now, the first thing any Unix user learns is that you shouldn't log in as root any more than you absolutely have to. The reasons for this are many: you can delete system files unintentionally, there's no log file to recreate disaster scenarios, and in general, you just don't need to do this. The first thing I do every time I'm on a new desktop Unix box is download a copy of sudo and install it. Then I change the root password to something long and forgettable, preferably with unpronounceable characters. I do this so that there's never any chance of me logging in as the super user again. I will say that this has caused me to have to boot from a root disk a time or two, but, on the other hand, I've never deleted a device file unintentionally.
Anyway, the purpose of that aside was to explain why I feel that you should always run your day to day tasks as a less privileged user. Even more so on Windows than on Unix, given the wider spread of Windows viruses and, to be honest, my lack of experience administering Windows. So, the first thing I did when I got this new computer was to create a non administrative user. Of course, for the first couple of days, I spent most of my time logged in as the administrative user, installing OpenOffice, Vim and other software. I also got my wireless card to work, which was simple. Plug in the card, have it find the SSID, enter the WEP key and I was in business.
That is, until I tried to access the Internet via my wireless card when logged in as the limited user. The network bounces up and down, up and down, and there doesn't seem to be anything I can do about it. Every second, the network changed status. To be honest, I haven't looked in google because I can't even think of how to describe the phenomenon. But, when I'm logged in as the administrator, it's smooth sailing. There are some things I plan to try, like creating another administrator and seeing if that account has similar problems. If that's the case, it's probably not the fact that my limited privilege account has limited privileges, but rather that the network software hasn't been made accessible to it. However, this situation is especially frustrating because the time when I least want to be logged in as an administrative user is when I'm most vulnerable to worms, viruses and rogue email attachments--that is to say, when I'm connected to the Internet.
I remember fighting this battle 3 years ago, when I was using Windows NT on a team of software developers. I was the only one (so far as I know) to create and use regularly a non privileged account. Eventually, I just said 'screw it' and did everything as the administrative user, much as I'll do now after a few more attempts to make the unprivileged user work. Windows just doesn't seem to be built for this deep division between administrators and users, and that doesn't seem to have changed.
January 28, 2004
How can you keep a website out of a search engine?
It's an interesting problem. Usually, you want your site to be found, but there are cases where you'd rather not have your website show up in a search engine. There are many reasons for this: perhaps because google never forgets, or perhaps because what is on the website is truly private information: personal photos or business documents. There are several ways to prevent indexing of your site by a search engine. However, the only sure fire method is to password protect your site.
If you require some kind of username and password to access your website, it won't be indexed from by any search engine robots. Even if a search engine finds it, the robot doing the indexing won't be able to move past the login page, as they won't have a username and password. Use a .htaccess if you have no other method of authenticating, since even simple text authentication will stop search engine robots. Intranets and group weblogs will find this kind of block useful. However, if it's truly private information, make sure that you use SSL because .htaccess access control sends passwords in clear text. You'll be defended from search engines, but not from people snooping for interesting passwords.
What if you don't want people to be forced to remember a username and password? Suppose you want to share pictures of baby with Grandma and Grandpa, but don't want to either force them to remember anything, nor allow the entire world to see your child dressed in a pumpkin suit. In this case, it's helpful to understand how search engines work.
Most search engines start out with a given set of URLs, often submitted to them, and then follow all the links in a relentless search for more content (for more on this, see this excellent tutorial). Following the links means that submitters do not have to give the search engine each and every page of a site, as well as implying that any page linked to by a submitted site will eventually be indexed as well. Therefore, if you don't want your site to be searched, don't put the web sites URL any place it could be picked up. This includes archived email lists, Usenet news groups, and other websites. Make sure you make this requirement crystal clear to any other users who will be visiting this site, since all it takes is one person posting a link somewhere on the web, or submitting the URL to a search engine, for your site to be found and indexed. I'm not sure whether search engines look at domain names from whois and try to visit those addresses; I suspect not, simply because of the vast number of domains that are parked, along with the fact that robots have plenty of submitted and linked sites to visit and index.
It's conceivable that you'd have content that you didn't want searched, but you did want public. For example, if the information is changing rapidly: a forum or bulletin board, where the content rapidly gets out of date, or you're EBay. You still want people to come to the web site, but you don't want any deep links. (Such 'deep linking' has been an issue for a while, from 1999 to 2004.) Dynamic content (that is, content generated by a web server, usually from a relational database) is indexable when linked from elsewhere, so that's no protection.
There are, however, two ways to tell a search engine, "please, don't index these pages." Both of these are documented here. You can put this meta tag: <meta name="robots" content="none"> in the <head> section of your HTML document. This lets you exclude certain documents easily. You can also create a robots.txt file, which allows you to disallow indexing of documents on a directory level. It also is sophisticated enough to do user-agent matching, which means that you can have different rules for different search engines.
Both of these latter approaches depend on the robot being polite and following conventions, whereas the first two solutions guarantee that search engines won't find your site, and hence that strangers will have a more difficult time as well. Again, if you truly want your information private, password protect it and only allow logins over SSL.
January 27, 2004
imap proxy and horde
I'm implementing an intranet using the Horde suite of tools. This is written in PHP, and provides an amazing amount of out of the box, easily configured functionality. The most robust pieces are the mail client (incidentally, used by WestHost for webmail, and very scalable), the calendar, and the address book. There are a ton of other projects using the Horde framework, but most of them are in beta, and haven't been officially released. Apparently these applications are pretty solid (at least, that's what I get from reading the mail list) but I wanted to shy away from unreleased code. I am, however, anxiously awaiting the day that the new version is ready; as you can see from the demo site that it's pretty sharp.
Anyway, I was very happy with the Horde framework. The only issue I had was that the mail application was very slow. I was connecting to a remote imap server, and PHP has no way to cache imap connections. Also, for some reason, the mail application reconnects to the imap server every time. However, someone on that same thread suggested using UP IMAP Proxy. This very slick C program was simple to compile and install on a BSD box, and sped up the connections noticeably. For instance, the authentication to the imap server (the only part of the application that I instrumented) went from 10 milliseconds to 1. It apparently caches the user name and password (as an MD5 hash) and only communicates with the imap server when it doesn't have the information needed (for example, when you first visit, or when you're requesting messages from your inbox). It does have some security concerns (look here and search for P_NEWLOG), but you can handle these at the network level. All in all, I'm very impressed with UP IMAP Proxy.
And, for that matter, I'm happy with Horde. I ended up having to write a small horde module, and while the framework doesn't give you some things that I'm used to in the java world (no database pooling, no MVC pattern) it does give you a lot of other stuff (an object architecture to follow, single sign-on, logging). And I'm not aware of any framework in the java world that comes with so many applications ready to roll out. It's all LGPL and, as I implied above, the released modules have a very coherent structure that makes it easy to add and subtract needed functionality.
Bravo Horde developers! Bravo imap proxy maintainer!
January 21, 2004
mod_alias to the rescue
Have you ever wanted to push all the traffic from one host to another? If you're using apache, it's easy. I needed to have all traffic from a http://www.foo.com site go to https://secure.foo.com. Originally, I was thinking of having a meta header redirect on the index.html page, and creating a custom 404 page that would also do a redirect.
Luckily, some folks corrected me, and showed me an easier way. mod_alias (ver 2.0) can do this easily, and as far as I can tell, transparently. I just put this line in the virtual server section for www.foo.com:
Redirect permanent / https://secure.foo.com/
Now, every request for any file from www.foo.com gets routed to secure.foo.com. And since they share the same docroot, this is exactly what I wanted.
To do this, make sure you have mod_alias available. It should be either compiled in (you can tell with httpd -l) or a shared library (on unix, usually called mod_alias.so). You have to make sure to load the shared library; see LoadModule and AddModule for more information.
January 17, 2004
IM Everywhere
The last two companies I worked at used instant messaging (IM) extensively in their corporate environment. They sent meeting notifications over IM, they used IM to indicate their availability for interactions, and they used it for the quick questions that IM is so good at handling ("hey John, can you bounce the server?"). IM has no spam, and is good at generating immediate responses.
I'm a latecomer to IM. I've used talk in college, but in a work environment, email was usually enough. And, I have to confess, when I'm programming, it's not easy for me to task switch. And IM demands that, in the same way that a phone call does. How many times have you been deep in a conversation with someone, only to have their phone ring? You know what happens next: they say "can I get that?" and reach for the phone. Whatever flow and connection you had is disrupted.
Now, obviously you can configure IM to be less intrusive than a phone call, and the first thing I did was switch off all sound notifications in my yahoo IM client. However, the entire point of IM is to disrupt what you're doing--whether it's by playing a sound or blinking or popping up a window, the attraction of IM is that it is immediate.
I've found that ninety percent of people would rather talk to a person than look something up for themselves. (I am one of those ninety percent.) There are a number of reasons. It's easier to ask unstructured questions. People are more responsive, and can come up with answers that you wouldn't think to find on your own. And it's just plain reassuring to find out what someone else thinks--you can have a mini discussion about the issue. This last is especially important if you aren't even sure what you're trying to find.
IM is a great help for this kind of ad-hoc discussion. However, it's another distraction at work. The real question is, do we need more distractions at work? Jakob Nielsen doesn't think so (see number 6) and I agree.
However, IM is becoming ingrained in these corporations, and I don't see anything standing in the way of further adoption. The original impetus to write this essay was the astonishment I felt at these two facts:
1. the widespread corporate use of IM
2. the paucity of corporate level control over IM
In all the time I was working at these companies, I saw many many IMs sent. But I only heard one mention of setting up a corporate IM server (someone mentioned that one of the infrastructure projects, long postponed, was to set up a jabber server). Now, I don't pretend that any corporate secrets were being exchanged, at least no more than are sent every day via unencrypted email. But every corporation of a decent size has control over its email infrastructure. I was astonished that no similar move had taken place yet for IM. Perhaps because IM is a young technology, perhaps because it is being rolled out from the bottom up, perhaps because it's not (always) a permanent medium.
For whatever reason, I think that you're going to see more and more IM servers (even MS has an offering) being deployed as businesses (well, IT departments) realize that IM is being heavily used and is not being monitored at all. Perhaps this is analogous to the explosion of departments static HTML intranets that happened in the late 1990s, which only came to an end when the IT department realized what was happening, and moved to standardize what became an important business information resource.
December 26, 2003
Comments on "Mobility is more than J2ME (and the job martket for 2004)", pt I
Michael Yuan had a pretty inflammatory post recently. Here are the first wave of my comments on this interesting topic.
"1. The move to mobility is inevitable in the enterprise. The IT revolution has to reach hundreds of millions of mobile workers in order to realize its promise. There is no other way. However, the real question is how and when this will happen. With the IT over-investment in the last decade, this might take several more years."
Agreed. Allowing mobile users to access the corporate datacenter is an inevitability. When it does happen, however, it certainly won't have the sexiness or big bang of the internet revolution. In fact, it's much more an evolution than a revolution. Folks already have access to corporate databases right now; the mobile revolution simply combines the portability of paper with the real time nature of laptops. However, letting knowledge workers such as sales people and truckers have real time information on such a cheap, reliable device really will change the nature of the business. But we won't see sock rabbits or dot.com millions, since such changes will favor existing businesses.
"2. When enterprises move to mobility, a key consideration is to preserve existing investment. Fancy flashy J2ME games will not do it. The task is often to develop specialized gateway servers and J2ME integration software to incorporate smart mobile frontends into the system. That requires the developers to have deep understanding of both J2EE and J2ME. I think that the "end-to-end" sector is where the real opportunities are in the next several years. That is also what "Enterprise J2ME" is all about. :)"
Now, don't be so quick to judge. Gamers pushed the boundaries of the PC in terms of computing power, and I wouldn't be surprised to see the same thing happen on the MIDP platform. That said, I'm not a gamer. However, I still have issues with the idea of folks paying to play a game on a cell phone. I play snake, but that's a simple, free game, and I'm certainly not dedicated to it. Fred Grott claims that MMORPGs are going to drive J2ME game development--I just don't see folks doing that when you can get a much, much richer experience from the XBox or Game Cube or PC sitting at home.
And I don't see why Michael ties J2ME and J2EE so tightly. The whole point of web services is to decouple the server and the client. I dont' see any reason why you couldn't have J2ME talk to a .NET server, or a BREW client talk to a J2EE server. To me, the larger issue with the mobile revolution is the architecture of the J2ME applications, since I think that such small, non networked, memory constrained applications (with either extremely limited portability or extremely limited user interfaces, take your pick) are going to be a world apart from the standard java developer's experience (which is HTML generation, not swing).
I'm going to leave his third point for another post, as the outsourcing issue is...worthy of a separate discussion.
December 01, 2003
Software as commodity
So, I was perusing the Joel On Software archives last night, and came upon Strategy Letter V in which Joel expounds on the economics of software. In particular, he mentions that commodifying hardware is easier than commodifying software. This is because finding or building substitutes for software is hard.
Substitutes for any item need to have the same attributes and behavior. The new hard drive that I install in my computer might be slower or faster, larger or smaller, but it will definitely save files and be accessible to my operating system. There are two different types of attributes of any substitute. There are required attributes (can the hard drive save files?) and ancillary attributes (how much larger is the hard drive?). A potential substitute can have all the ancillary features in the world, but it isn't a substitute until it has all the required features. The catch to building a substitute is knowing what are required and what are ancillary--spending too much time on ancillary can lead to the perfect being the enemy of the good, but spending too little means that you can't compete on features (because, by definition, all your viable competitors will have all the required features). (For an interesting discussion of feature selection, check out this article.)
Software substitutes are difficult because people don't like change (not in applications, not in URLs, not in business). And software is how the user interacts with the computer, so the user determines the primary attributes of any substitute. And those are different with every user, since every user uses their software in a different manner.
But, you can create substitutes for software, especially if
- The users are technically apt (because such users tend to resent learning new things less).
- You take care to mimic user interfaces as much as you can, to minimize the new things a user had to learn.
- It's a well understood problem, which means the solutions are probably pretty well understood also (open standards can help with this as well)
Bug tracking software is an example of this. Now, I'm not talking about huge defect tracking systems like Rational's ClearCase that can, if you believe the marketing, track a bug throughout the software life cycle, up into requirements and out into deployment. I'm talking about tools that allow small teams to write better code by making sure nothing slips between the cracks. I've worked with a number of these tools, including Joel's own FogBUGZ, TestTrack, Mozilla's Bugzilla and PHPBT. I have to say that I think the open source solutions (Bugzilla and PHPBT) are going to eat the commercial solutions' lunch for small projects, because they are a cheaper substitute with all the required attributes (bug states, email changes, users, web access).
I used to like Bugzilla, but recently have become a fan of PHPBT because it's even simpler to install. If you have local access to sendmail, a mysql database and a web server (all of which WestHost provides for $100/year or you can get on a $50 Redhat CD and install on a old Intel box). It tracks everything that you'd need to know. It ain't elegant, but it works.
I think that in general, the web has helped to commodify software, just because it imposes a certain uniformity of user interface. Everyone expects to use forms, select boxes, and the back button. However, as eBay knows and Yahoo! Auctions found out, there are other factors that prevent substitution of web applications.
November 13, 2003
Amazon Web Services
I remember way back when, in 2000, when EJBs were first hot. Everyone wanted to use EJBs in projects, mostly for the resume value. But there was also a fair bit of justified curiosity in this new technology that was being hyped so much. What did they do? Why were they cool? How did they help you?
I did some reading, and some research, and even implemented one or two toy EJBs. I remember talking to a more experienced colleague, saying "Well, all EJBs provide you is life-cycle assistance--just automatic pooling of objects, a set of services you can access, transaction support, and maybe SQL code generation." Now, I'm young and inexperienced enough to never have had the joy of doing a CORBA application, but my colleague, who I believe had had the joy of doing one or three of those, must have been rolling her eyes when I said this. 'Just' life-cycle assistance, eh?
I just looked at Amazon's web services, and I'm beginning to understand how she felt. Sure, all web services provides you is easy, (relatively) standardized access to the resources and data available in a web application. Sure, I could get the same information by screen-scraping (and many an application has done just that). But, just as EJB containers made life easier by taking care of grimy infrastructure, so do web services make life easier by exposing the information of a web application in a logical format, rather than one dependent on markup.
Using perl and XSLT (and borrowing heavily from the Developer Kit, I built an application using Amazon's web services (the XML over HTTP API, not the full SOAP API). I was amazed at how easy it was to put together. This was partly due to the toy-like nature of the application, and how much it leveraged what Amazon already provided, but it was also due to the high level of abstraction I was able to use. Basically, Amazon exported their data model to me, and I was able to make small manipulations of that model. It took me the better part of three hours to put together an application which allows you to search on a keyword or ISBN and gives all the related books that Amazon has for that book. You know, the 'Customers who bought this book also bought' section.
I've always felt that that was the most useful bit of Amazon, and a key differentiator. This feature, as far as I can tell, leverages software to replace the knowledgeable bookstore employee. It does this by correlating book purchases. This software lends itself to some interesting uses. (I wanted to have a link to an app I found a while ago, where you entered two different artists/authors and it found the linkage between the two. But I can't find it!)
I like this feature, but it also sucks. The aforementioned bookstore employee is much better than Amazon. Buying a book doesn't mean that I'll enjoy it--there are many books I've purchased that I wonder why I did so, even one hour after leaving the store--so that linkage isn't surefire. In addition, purchase is a high barrier, and will probably cause me to not branch out as much as I should--rather than waste my money picking a random book, I'll pick a book from an area I know. The book store employee, if good, can overcome both of these faults, because the process is more interactive, and the suggester has intelligence. But he doesn't scale nearly as well as cheaply, nor does he have the breadth of Amazon's database. (And he hates staying up all night responding to HTTP requests.)
Amazon Web Services
I remember way back when, in 2000, when EJBs were first hot. Everyone wanted to use EJBs in projects, mostly for the resume value. But there was also a fair bit of justified curiosity in this new technology that was being hyped so much. What did they do? Why were they cool? How did they help you?
I did some reading, and some research, and even implemented one or two toy EJBs. I remember talking to a more experienced colleague, saying "Well, all EJBs provide you is life-cycle assistance--just automatic pooling of objects, a set of services you can access, transaction support, and maybe SQL code generation." Now, I'm young and inexperienced enough to never have had the joy of doing a CORBA application, but my colleague, who I believe had had the joy of doing one or three of those, must have been rolling her eyes when I said this. 'Just' life-cycle assistance, eh?
I just looked at Amazon's web services, and I'm beginning to understand how she felt. Sure, all web services provides you is easy, (relatively) standardized access to the resources and data available in a web application. Sure, I could get the same information by screen-scraping (and many an application has done just that). But, just as EJB containers made life easier by taking care of grimy infrastructure, so do web services make life easier by exposing the information of a web application in a logical format, rather than one dependent on markup.
Using perl and XSLT (and borrowing heavily from the Developer Kit, I built an application using Amazon's web services (the XML over HTTP API, not the full SOAP API). I was amazed at how easy it was to put together. This was partly due to the toy-like nature of the application, and how much it leveraged what Amazon already provided, but it was also due to the high level of abstraction I was able to use. Basically, Amazon exported their data model to me, and I was able to make small manipulations of that model. It took me the better part of three hours to put together an application which allows you to search on a keyword or ISBN and gives all the related books that Amazon has for that book. You know, the 'Customers who bought this book also bought' section.
I've always felt that that was the most useful bit of Amazon, and a key differentiator. This feature, as far as I can tell, leverages software to replace the knowledgeable bookstore employee. It does this by correlating book purchases. This software lends itself to some interesting uses. (I wanted to have a link to an app I found a while ago, where you entered two different artists/authors and it found the linkage between the two. But I can't find it!)
I like this feature, but it also sucks. The aforementioned bookstore employee is much better than Amazon. Buying a book doesn't mean that I'll enjoy it--there are many books I've purchased that I wonder why I did so, even one hour after leaving the store--so that linkage isn't surefire. In addition, purchase is a high barrier, and will probably cause me to not branch out as much as I should--rather than waste my money picking a random book, I'll pick a book from an area I know. The book store employee, if good, can overcome both of these faults, because the process is more interactive, and the suggester has intelligence. But he doesn't scale nearly as well as cheaply, nor does he have the breadth of Amazon's database. (And he hates staying up all night responding to HTTP requests.)
November 10, 2003
Yahoo! mail problems
One of my clients had a problem earlier today. I helped them choose a new email setup, and they went with Yahoo Business Edition Mail. It's worked like a charm for them until today. Oh, sure, they've had to adjust their business processes a bit, but it was a vast improvement over their previous situation, where only allowed one person in to view his or her mailbox at a time. And it's quite low maintenance and fairly easy to learn, as it was entirely browser based.
But today, the web client for Yahoo! was busted. New layouts, new colors, old functionality gone, intermittent changes in the GUI, the whole bit. I got on the phone with Yahoo! support, and they assured me it was simply a webmail client problem. No mail was being lost. But, as Joel explains, for most folks, the interface is the program. You try explaining the difference between SMTP and POP and mail storage and local clients to an insurance agent who just wants to send her customers an application.
One of the worst bits is that, other than getting on the phone with Yahoo! support, there was absolutely nothing I could do to fix the problem. Alright, this isn't entirely true--I could have worked on migrating them off the web client, and perhaps off Yahoo! entirely. And, had the outage continued, I probably would have begun that process. But fixing the web client was entirely out of my hands. That's the joy and the pain of outsourcing, right? The problems aren't yours to fix (yay!) but you can't fix the problems yourself (boo!). Also, chances are the outsourcing provider is never going to be more enthusiastic than you about fixing your problems, and might be significantly less.
Put the pieces together: A Linux Small Business Server
I noticed an article on InfoWorld about Microsoft Small Business Server (SBS). This software package brings together important software packages for small business organizations in an easy to configure and install bundle. The primary features of SBS are, according to this article, email and calendaring, file and printer sharing, and file backup. There are additional features that you can plug in, including email clients, a fax server, remote access via the web, and possibly integration with a back end database.
All this software exists for Linux. For email, you have qmail and imap (we aren't concerned about the client, because they'll use Outlook, if they have Office). For calendaring, I haven't found anything quite as slick as Outlook, but Courier promises web based calendaring, and Mozilla Calendar, when paired with a WebDAV enabled web server, like Apache with mod_dav, allows you to share calendars (it does require you to install the Mozilla browser on every client, though). For file and print sharing, there's Samba and for backups, there's the super stable Amanda. Remote access can be handled via VNC and fax server solutions can be built, although the author of the InfoWorld article prefers a fax over IP service which should work fine as long as you have MS Office. As for back end databases, you'd probably want PostgreSQL, probably managed via MS Access. Wrap it all up with Webmin for administration. (Full disclosure--I haven't used all this software, just most of it.)
So, I set out on the web to see if anyone had gathered all these components together, tested them, and made it easy to install and configure. Basically, an SBS competitor that could compete on features, with the added bonus of Linux's open nature and stability.
First, I checked out what Redhat and SuSe (1, 2) had to offer. While they had standard servers that were cheaper than the $1500 quoted for SBS, the Linux packages didn't have all the features either. Then, I did a web search, which didn't turn up much, except for a LUG project: the Windows Replacement Network. I'm not sure how active this project is, but at least it's a start. I checked on SourceForge, but didn't see anything that looked similar.
I really think that there's an enormous opportunity for the open source community to piggy back off of MS. They've already done the market research, they've already determined the feature set that will sell to small businesses. And almost all the software is written for the Linux version of the SBS--all that really needs to happen is some configuration and documentation to make all these features work together. Cut it to a CD-ROM and start passing them out at LUG meetings. This would provide one more option in a consultant's toolbox and give consumers one more choice.
October 28, 2003
Why open source?
http://web.mit.edu/wwwdev/cgiemail/buybuild.html has an eloquent explanation of some of the motivating factors behind the open source movement.
In case you aren't a computer geek, the term open source (free software is another name) refers to computer programs that you can download and share with your friends. Licenses vary, but a common one (the GPL) specifies that you can do whatever you want with the software that is licensed under it, but if you redistribute any changes, you have to make them available under the same terms that the code was originally made available to you.
Some software is core business software. I was talking to a consultant who dealt with telecommunications companies. Their billing and minute tracking software really is part of their core competency. You can use that software to actually make the company more efficient in scalable ways. Ditto companies that make pace-makers--the software is entwined with their hardware and is really integral to the product.
But for many businesses, there are huge swathes of software that aren't integral in the same way. Their needed, but for their supporting functionality, not for the processes that they enable. For example, the web server that hosts a company's web pages is not integral. The office suite is not a fundamental part of your business processes. The macros and files and VB programs that you write on top of an office suite probably are, but the bland office suite is not.
When software is written that defines a business process, then it is integral. When it's a supporting platform for the business process, it's not. And, as Bruce argues in the article above, when it isn't integral, there are very good reasons to push the software out into the world and share the cost of maintenance.
Oh, and any discussion of open source software would be remiss if it didn't link to The Cathedral and the Bazaar.
October 21, 2003
How I secured my wireless network
Update: Check out this page for more on securing linksys access points: http://www.worldwidewardrive.org/linksys/linksys1.html
I have a wireless network running around my home. I don't really use it--I struggled to get 802.11b working on my (old) Linux workstation last year, and failed. But my roommate does use it. She had a friend come in and install a wireless switch (into which I plugged my tired old wired workstation) and a card into her computer. With all the defaults set, it worked like a charm.
I ignored it for a month. But then I was at a friend's house and he turned on his laptop, searched for a wireless connection, and was soon surfing on his neighbor's broadband connection. Now, I don't have any state secrets, but this worried me. So, I asked my friend how to secure the wireless network that I had. He gave me three easy steps:
1. Change the router password. If you don't do this, a simple Google search for 'linksys default password' can compromise your entire system. Sure, if you need to you can probably hardware reset the password, but who needs the hassle.
2. Change the SSID. I don't have any idea what this is, but do change it from the default. This requires changing both the server (the router) and the client (software on my roommate's computer).
3. Enable WEP. This is a 128 bit encryption protocol. It's not supposed to be very secure, but, as my friend said, it's like locking your car--a thief can still get in, but it might make it hard enough to not be worth their while. This entailed picking a key, and making some configuration changes on both the server and the client.
In short, it was super easy to do. Wireless in general is an amazingly easy technology, and if I was building a small office nowadays, I certainly wouldn't wire the workstations. The bandwidth that 802.11b supports is easily enough to saturate a broadband connection, and the security features, while not bullet proof, are probably not going to be the weak point of a small office (the weak point will probably be weak passwords). The ease of use and of adding new workstations certainly makes wireless a compelling solution.